
Chapter 10The Transformer Architecture, Explained Simply
The transformer is the single most important invention behind modern AI. Every model you have heard of is built on it. Yet its core idea is surprisingly graspable, and you do not need any equations to truly understand it. In this chapter we take the transformer apart piece by piece, using pictures and analogies, until the word *attention* stops being jargon and starts being obvious. By the end you will understand not just how a transformer works, but *why* this particular design unlocked everything that followed.
The Problem Transformers Solved
To appreciate the transformer, you have to know what came before it. Earlier language models read text the way you might read through a drinking straw — one word at a time, strictly left to right, trying to hold everything important in a small mental buffer as they went. These models, called recurrent networks, had two painful weaknesses.
- They were slow. Because each word's processing depended on the result from the previous word, the work could not be split up. It had to happen in a strict sequence, like a line of people passing a bucket one at a time.
- They forgot. By the time the model reached the end of a long paragraph, the beginning had faded — much as you might lose the start of a very long, winding sentence by the time you reach its end.
The transformer, introduced in 2017, swept both problems away with a single bold move: let every word look at every other word directly, all at once. That one idea is the whole revolution. Everything else in this chapter is just the machinery that makes it work.
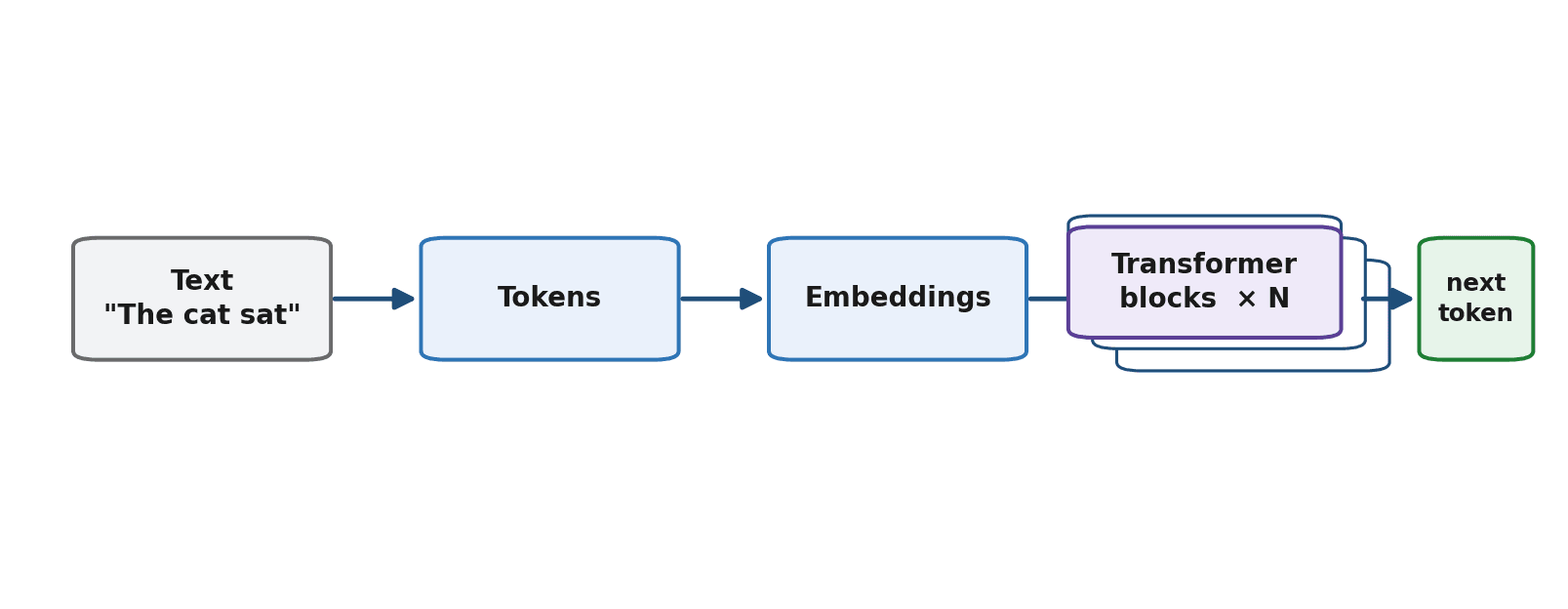
The Big Picture First
Before we open up any single part, here is the whole journey a sentence takes through a transformer, viewed from a comfortable distance. Hold this map in mind and the details will have somewhere to attach.
- The text is split into tokens — small pieces, roughly word-sized (Chapter 11 covers exactly how).
- Each token becomes an embedding — a list of numbers representing its meaning.
- The embeddings flow through a tall stack of identical transformer blocks, each one refining them a little further.
- After the final block, the model uses the refined numbers to predict the next token.
Almost everything interesting happens in step 3, inside those stacked blocks. And the beating heart of every block is the mechanism we will now meet: attention.
Attention: The Core Idea
Read this sentence: "The dog chased the ball because it was excited." What does it refer to — the dog or the ball? You knew instantly: the dog. But notice what you had to do to know that. You could not understand it by looking at it alone; you had to glance back at the other words and decide which one it was connected to. Attention is exactly that ability, built into the model. For every word, the model decides which other words to look at, and how much weight to give each one.
Picture each word holding a spotlight that it can shine across the whole sentence. When the model processes it, that word's spotlight lands brightly on dog and only dimly on the rest. The bright words are the ones whose meaning gets pulled in to help interpret the current word. Every word does this for every other word, simultaneously.
Mechanically, the intuition goes like this. Each word produces a query — in effect, the question "what am I looking for?" Every word also offers a key — a label announcing "here is what I am." The model matches each query against all the keys to decide how much attention to pay to each word, then gathers a weighted blend of the words it attended to (their values). Query, key, value: a question, matched against labels, retrieving content.
In rough pseudocode, the attention each word performs looks like this:
for each word:
scores = how_well_my_query_matches(every_key) # relevance to each other word
weights = softmax(scores) # turn scores into shares of attention
new_meaning = weighted_sum(weights, values) # blend in what I attended toThe one new term there is softmax. It simply turns a set of raw relevance scores into a set of weights that add up to 1 — a tidy way of dividing one hundred percent of a word's attention among all the words it could look at. High score, large share; low score, small share.
Why "Self"-Attention, and Why Many Heads
Because the words are attending to each other within the same sentence, this is called self-attention. Now for a refinement that adds much of the transformer's power. A single spotlight can only track one kind of relationship at a time, but real language carries many relationships at once: grammatical ones (which noun goes with which verb), referential ones (what it points to), and thematic ones (which words share a topic).
So transformers use multi-head attention: several spotlights running in parallel, each free to specialize in a different kind of relationship. One head might learn to track pronouns and what they refer to; another might follow subject-verb agreement; another might group words by topic. Their separate findings are then combined into a single richer representation of each word.
Telling the Model the Word Order
Here is a subtlety that trips up almost everyone at first. Because every word looks at every other word all at once, the transformer has no built-in sense of order. To it, a sentence arrives more like a bag of words than a sequence. But order obviously matters enormously: "dog bites man" and "man bites dog" contain the same words and mean opposite things.
The fix is positional information. Before the words enter the blocks, each embedding is tagged with a signal encoding its position — first, second, third, and so on. Think of it as assigning every passenger a numbered seat as they board: the model can now tell who sits where, and therefore take word order into account when it pays attention.
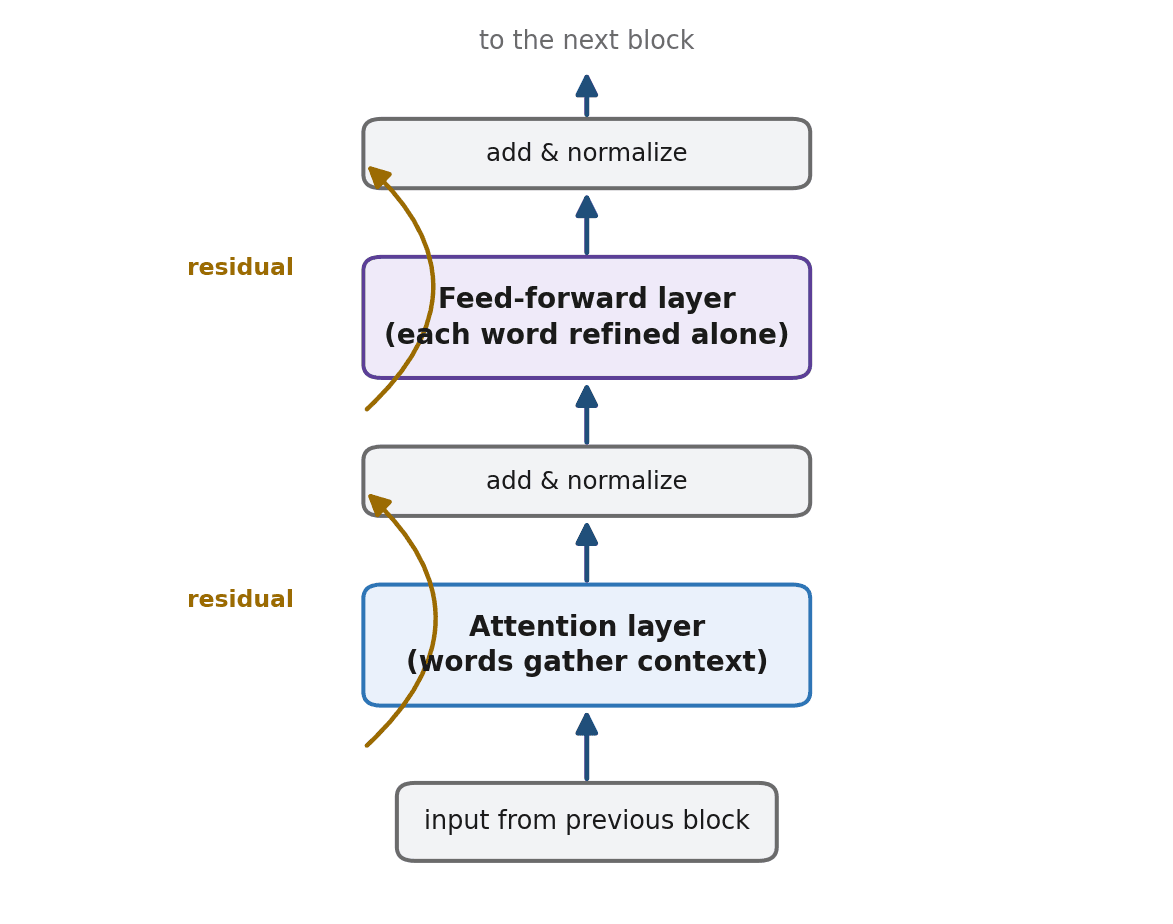
Inside a Single Transformer Block
We now have everything we need to assemble one block. Each block does two main things in turn, then wraps them in two stabilizing tricks.
- Attention layer. Every word gathers information from the others, exactly as described above. After this step, each word's representation has been enriched by its context.
- Feed-forward layer. Each word — now aware of its surroundings — is passed individually through a small network that processes and refines it further. Attention mixes words together; the feed-forward step then thinks about each word on its own.
Around those two layers sit two quiet but essential helpers:
- Residual connections. Each layer adds its output to its input rather than replacing it, so nothing learned earlier is ever thrown away. It is like editing a draft by adding margin notes instead of rewriting the page from scratch.
- Normalization. This keeps the numbers flowing through the block in a sensible range so that training stays stable — rather like periodically tidying your workspace so the work does not slide into chaos.
Stacking Blocks Into Depth
One block refines the word representations a little. A modern language model stacks many such blocks — often dozens or more — one on top of another. Each block's output becomes the next block's input, and with every layer the representations grow richer and more abstract.
A pleasing pattern tends to emerge across the depth. Early layers mostly capture surface features: which words sit nearby, simple grammar. Later layers capture more abstract meaning: the overall topic, the speaker's intent, subtle relationships between distant ideas. Depth is where shallow pattern-matching gradually turns into something that behaves like understanding.
From Numbers Back to Words
After the final block, the model holds a richly refined representation for the position whose next token it is trying to predict. It converts that representation into a score for every possible token in its vocabulary, then uses softmax once more to turn those scores into probabilities. It can pick the single most likely token, or sample among the likely ones to add variety. It appends the chosen token and repeats the whole process to generate text one token at a time.
Why This Design Conquered AI
Two advantages, both flowing directly from the founding idea that every word looks at every word at once, explain why the transformer swept the field.
- Speed through parallelism. Because words are processed together rather than strictly one after another, the work can be spread across many processors at the same time. This made it practical to train on vast quantities of text in a reasonable time.
- Long-range memory. A word at the very end of a long passage can attend directly to a word at the very beginning, with no fading in between. The forgetting problem that crippled earlier models largely disappears — at least within the context window, which Chapter 12 explores.
These two properties are why, when researchers poured more data and built bigger models on the transformer design, the results kept improving instead of stalling. The architecture scaled gracefully where older designs hit a wall — and that scalability, as much as the design itself, is what brought us to the present moment.
Summary
The transformer replaced slow, forgetful sequential models with one powerful idea: every word attends to every other word, all at once. Attention lets each word pull in meaning from the words most relevant to it; multiple heads track several kinds of relationship in parallel; positional tags restore the sense of order; and each block pairs an attention layer with a feed-forward layer, steadied by residual connections and normalization. Stacked deep, these blocks turn raw embeddings into rich representations, from which the model predicts the next token. The design conquered AI because it is both fast to train and good at long-range memory.
Next, Chapter 11 zooms in on the very first step we glossed over — tokenization, how raw text becomes tokens in the first place — and Chapter 12 returns to attention to examine the all-important context window in depth.
Exercises
- 1In the sentence "The trophy didn't fit in the suitcase because it was too big," identify what "it" refers to, and describe in attention terms what the model must do to resolve it. Now change "big" to "small" and explain how and why the answer flips.
- 2Explain, to an imagined friend with no technical background, what "attention" means in a transformer. Invent your own analogy rather than reusing the spotlight one from this chapter.
- 3List, in order, the four stages a sentence passes through from raw text to a next-token prediction.
- 4Why do transformers need to be given positional information when older sequential models did not? Answer in two or three sentences.
- 5A transformer uses many attention heads rather than one. Explain why several heads are more powerful than a single head, and why we do not tell each head in advance what to specialize in.
- 6Open any LLM playground and give the model several sentences containing an ambiguous pronoun (like "it" or "they"). Ask the model what each pronoun refers to. Note where it succeeds and where it stumbles, and connect what you see back to the idea of attention.