
Chapter 16Cleaning, Deduplicating, and Filtering Data
If Chapter 15 was about choosing your ingredients, this chapter is about washing and chopping them. Raw data — especially raw web text — is genuinely filthy: full of duplicates, junk, broken formatting, and content you do not want anywhere near your model. Cleaning it is unglamorous, hands-on work, and it is some of the highest-leverage work in all of machine learning. We will walk through a practical cleaning pipeline step by step, with runnable code you can adapt to your own datasets, and we will see exactly why one step — deduplication — matters far more than beginners expect.
Raw Data Is a Mess
It is hard to overstate how messy raw text is before cleaning. A single scraped web page might give you the article you wanted, wrapped in navigation menus, cookie banners, advertisements, social-media buttons, leftover formatting markup, and a comment section full of spam. Multiply that by billions of pages and you have a mountain of noise around every nugget of signal.
Imagine pulling text from a page and getting something like: a chunk of HTML tags, then "Home | About | Contact," then the actual sentence you wanted, then "Click here to subscribe!!!," then the same sentence again because it appeared twice on the page. Training on that as-is would teach the model that navigation menus and subscribe buttons are a normal part of language. Cleaning removes the noise so the model learns from the signal.
The Cleaning Pipeline Overview
Cleaning is best thought of as a pipeline: a sequence of steps, each one taking in text and passing cleaner text to the next. A typical pipeline normalizes the text, filters out junk, removes duplicates, and strips harmful or private content. We will build each step in turn and then combine them.
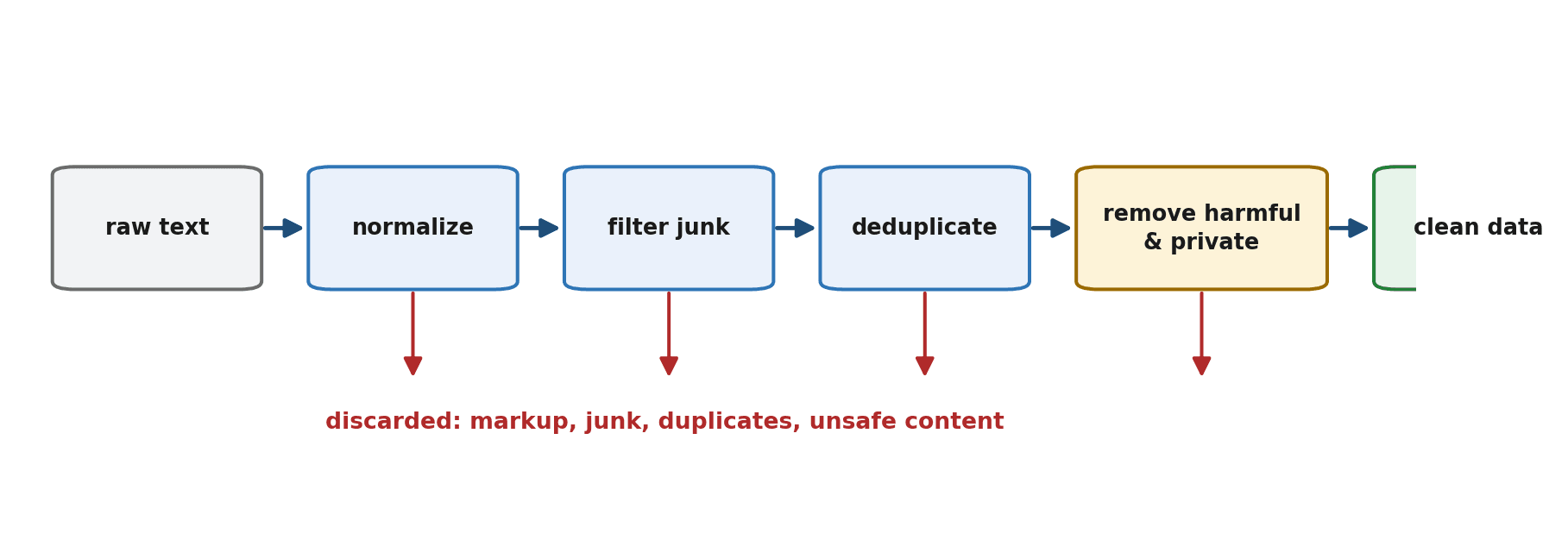
Step 1: Normalize the Text
Normalizing means putting text into a consistent, tidy form: stripping out leftover markup, collapsing messy whitespace, and fixing formatting. A small amount of normalization removes a surprising amount of noise. Notice the trick in the whitespace step — splitting on any whitespace and rejoining with single spaces collapses tabs, newlines, and runs of spaces all at once, with no complicated patterns.
import re
def normalize(text):
text = re.sub(r"<[^>]+>", "", text) # remove HTML tags like <div>
text = " ".join(text.split()) # collapse all whitespace to single spaces
return text.strip() # trim leading/trailing space
messy = "<p>Hello world </p>\n\n Welcome! "
print(normalize(messy)) # "Hello world Welcome!"This is intentionally simple. Real pipelines do more, but the spirit is the same: make the text uniform so that later steps and the model itself are not distracted by formatting noise.
Step 2: Filter Out Junk
Not every piece of text is worth keeping. Filtering discards entries that are too short to be useful, suspiciously long, mostly symbols or gibberish, or otherwise low quality. These filters are usually simple rules of thumb, and simple is fine — the goal is to remove the obvious junk, not to achieve perfection.
def is_good_quality(text):
words = text.split()
if len(words) < 5: # too short to be useful
return False
if len(words) > 5000: # suspiciously long; likely junk
return False
# require a reasonable fraction of normal letters
letters = sum(c.isalpha() or c.isspace() for c in text)
if letters / max(len(text), 1) < 0.6:
return False
return True
documents = [d for d in documents if is_good_quality(d)]Step 3: Remove Duplicates (Deduplication)
Deduplication removes repeated content, and it is more important than almost any other cleaning step — important enough that we devote the next section entirely to why. The simplest form catches exact duplicates using a set, which automatically keeps only unique items.
def deduplicate_exact(documents):
seen = set()
unique = []
for doc in documents:
if doc not in seen:
seen.add(doc)
unique.append(doc)
return unique
print(len(documents), "->", len(deduplicate_exact(documents)))Exact deduplication only catches text that is identical. In practice, much duplication is near-duplication — the same article with a different headline, or a page copied with minor edits. Catching those requires comparing documents for similarity (often using fast hashing techniques, and conceptually related to the embeddings of Chapter 9). The details are beyond this chapter, but be aware that exact matching is only the first layer.
Step 4: Remove Harmful and Private Content
The final step filters out content you never want a model to learn: toxic or abusive material, and personal or private information such as names paired with addresses, identification numbers, and the like. In a real pipeline this uses specialized detectors; conceptually, it is just another filter that drops anything flagged.
def is_safe(text):
# In practice these checks use trained detectors and careful rules.
if contains_toxic_content(text): # abusive / harmful material
return False
if contains_personal_info(text): # names, addresses, IDs, etc.
return False
return True
documents = [d for d in documents if is_safe(d)]Removing private data is not only an ethical duty but a practical one: a model that memorized someone's personal details could later reproduce them, which is both harmful and, in many places, unlawful.
Why Deduplication Matters So Much
It is worth pausing on duplicates, because their harm is easy to underestimate. Three serious problems follow from leaving them in.
- Over-weighting. If a passage appears a thousand times in the training data, the model effectively sees it a thousand times and gives it outsized importance, skewing what it learns.
- Memorization. Heavily repeated text is more likely to be memorized verbatim — which is exactly how a model can end up reproducing private information or copyrighted passages word for word.
- Test-set contamination. This is the most insidious. Recall from Chapter 6 that we must test on data the model has never seen. If duplicates cause your test examples to also appear in the training data, your evaluation scores become a lie — the model looks brilliant because it is reciting answers it already saw.
Putting a Simple Pipeline Together
Each step is modest on its own; their power comes from chaining them. Here they are combined into one pass over a collection of documents.
def clean_dataset(documents):
documents = [normalize(d) for d in documents] # step 1
documents = [d for d in documents if is_good_quality(d)] # step 2
documents = deduplicate_exact(documents) # step 3
documents = [d for d in documents if is_safe(d)] # step 4
return documents
clean = clean_dataset(raw_documents)
print("Kept", len(clean), "of", len(raw_documents), "documents")Run this and you will typically discard a large fraction of your raw data — and that is a success, not a failure. The documents that survive are the ones worth learning from.
Cleaning for Your Own Datasets
These principles scale all the way down to the small datasets you will build for fine-tuning (Chapter 17) or the documents you load into a RAG system (Chapter 36). Even with only a few hundred examples, you should normalize formatting, drop junk and near-duplicates, and check for anything harmful or private. A small dataset that is impeccably clean will outperform a larger careless one every time. Cleaning is not a chore reserved for giant labs; it is a habit that pays off at any scale.
Summary
Raw data, especially from the web, is full of noise, and cleaning it is among the highest-leverage work in machine learning. A practical pipeline normalizes text into a consistent form, filters out junk by simple quality rules, deduplicates, and removes harmful and private content — and chaining these steps typically discards much of the raw data, which is the point. Deduplication deserves special care because duplicates cause over-weighting, memorization, and the worst sin of all, test-set contamination that renders evaluation meaningless. The same cleaning discipline applies to the small fine-tuning and retrieval datasets you will build yourself.
With clean data in hand, we can start shaping a model's behavior. Chapter 17 builds the first kind of behavior-shaping dataset: instruction–response pairs that turn a base model into one that follows your requests.
Exercises
- 1Implement the `normalize` function and run it on a messy string of your own that contains HTML tags, extra spaces, and line breaks. Confirm it produces clean single-spaced text.
- 2Write a quality filter that removes documents shorter than a threshold you choose, run it over a small list of sample documents, and report how many remain.
- 3Implement exact deduplication with a `set` over a list that deliberately contains some repeats. Show the count before and after.
- 4Explain, in your own words, the three distinct ways that leaving duplicates in training data can harm the result. Which of the three do you think is most dangerous, and why?
- 5Describe test-set contamination and connect it back to the train/test rule from Chapter 6. Why does it make a model's reported scores untrustworthy?
- 6Take a small dataset you care about (even a handful of text files), run it through the combined `clean_dataset` pipeline idea, and write a sentence on what was removed and why keeping it would have hurt.