
Chapter 18Preference and RLHF Data: How Human Feedback Is Collected
Instruction tuning, from the last chapter, teaches a model to follow requests. But it leaves a subtler question unanswered: when two responses are both reasonable, which is *better* — more helpful, more honest, safer, better phrased? Teaching that judgment requires a different kind of data, built not from single right answers but from human *preferences* between alternatives. This chapter explains what preference data is, why it takes the form of comparisons, how it is collected, and the genuine difficulties involved. The training methods that consume this data come in Part V; here we focus entirely on the data itself.
The Limit of Instruction Tuning
Instruction tuning works by showing the model a single ideal response per instruction. That is perfect when there is a clear right answer, but much of what makes an assistant good is not about right versus wrong. It is about better versus worse. Two answers might both be correct, yet one is clearer, kinder, more concise, or safer. How do you teach a model to prefer the better one when both are acceptable?
You cannot easily capture this with single examples, because the lesson is comparative by nature. So instead of asking "what is the right answer?", we ask humans a different question: "between these two answers, which do you prefer?" The data built from those judgments is called preference data, and learning from it is the heart of modern alignment.
What Preference Data Is
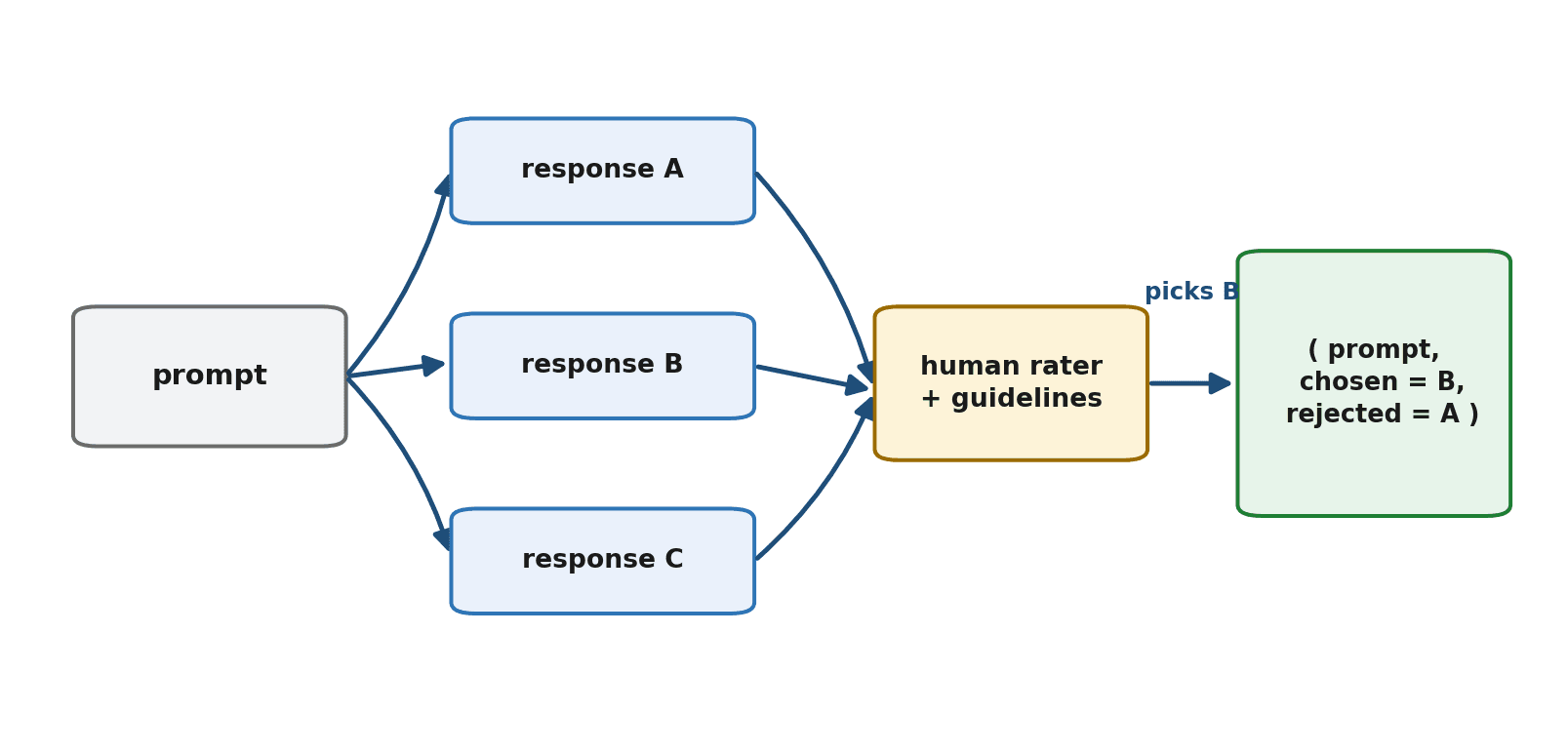
A piece of preference data is a comparison. You take a single prompt, generate two or more candidate responses, and record which one a human judged better. The result is usually stored as a triple: the prompt, the chosen (preferred) response, and the rejected response.
{
"prompt": "I'm feeling overwhelmed at work. Any advice?",
"chosen": "That sounds really tough. A few things can help: list your tasks "
"and tackle the smallest first, take short breaks, and consider "
"talking to your manager about workload. What feels most pressing?",
"rejected": "Just work harder and you'll get through it."
}Both responses are on-topic, but most people would clearly prefer the first: it is empathetic, specific, and helpful, while the second is dismissive. The triple captures that judgment in a form a training process can later learn from.
Why Comparisons Instead of Scores?
Why ask which is better, rather than asking a rater to score each response from one to ten? Because humans are unreliable at absolute scores but reliable at relative comparisons. If you ask someone whether a response is a 7 or an 8, their answer drifts with their mood, the time of day, and what they just saw. But ask whether response A is better than response B, and people are remarkably consistent. Comparison sidesteps the impossible task of pinning meaning to a number, and it is why preference data is built from pairwise choices rather than ratings.
How the Data Is Collected
The collection pipeline is conceptually straightforward. For each prompt, the model generates several candidate responses. Human raters then review them and indicate which they prefer, guided by a written set of guidelines describing what "better" means for this project. Those guidelines are doing enormous work: they are where the values of the system are actually specified — what counts as helpful, what counts as harmful, how to weigh competing qualities. Vague guidelines produce noisy, inconsistent data; careful ones produce data a model can actually learn from.
What Raters Look For
Across most projects, raters are asked to judge responses along a few core dimensions, often summarized as being helpful, honest, and harmless. A good response actually addresses the request (helpful), does not make things up or mislead (honest), and avoids causing harm (harmless). The interesting difficulty is that these can pull against each other. The most helpful-seeming answer to a dangerous request would be harmful; the most cautious answer might be unhelpful. Much of the craft in the guidelines is specifying how to resolve these tensions, and reasonable people sometimes disagree about the right resolution.
From Comparisons to a Better Model
How does a pile of comparisons make a model better? At a high level, the preference data is used to teach the model to produce the kinds of responses humans tended to choose, and to avoid the kinds they tended to reject. There are a few concrete techniques for doing this — training a separate "reward model," or the more direct methods that have largely succeeded it — and we cover them properly in Chapter 24. For now, hold the bridge in mind: comparisons go in, and a model better aligned with human preferences comes out.
The Connection to Reinforcement Learning
This is where a thread from Chapter 6 pays off. Recall that reinforcement learning means learning from rewards rather than from labelled answers. Preference data provides exactly that: human preferences become a reward signal, rewarding responses people prefer and penalizing those they reject. This is the origin of the term RLHF — Reinforcement Learning from Human Feedback. The "human feedback" is the preference data of this chapter; the "reinforcement learning" is the machinery of Part V that turns it into an improved model.
The Challenges of Human Feedback
Collecting good preference data is genuinely hard, and it is worth being honest about why.
- It is expensive and slow. Every comparison requires human attention, which does not scale cheaply the way scraping text does.
- It is subjective. Different raters genuinely prefer different things, and even the same rater can be inconsistent across a long session.
- Guidelines carry values. Whoever writes the rating guidelines is, in effect, deciding what the model should consider "better" — a position of real influence that deserves scrutiny.
- Whose preferences? A pool of raters is never a perfect mirror of all the people a model will serve, so the resulting values can reflect some groups more than others.
- Disagreement is real. On contested questions, there may be no single "better" answer that everyone would endorse, and the data smooths over disagreements that matter.
Preference Data in Practice
For your own projects, you can collect preference data at small scale to tune a model toward the behavior you want. The structure is simple — generate candidates, choose the better one, store the triple — and a modest number of careful comparisons can meaningfully shift a model's style.
# A small preference dataset is just a list of comparison triples.
preferences = [
{"prompt": "Explain recursion to a beginner.",
"chosen": "Recursion is when a function calls itself to solve a smaller "
"version of the same problem, like looking up a word whose "
"definition sends you to another word.",
"rejected": "Recursion is a function that is recursive."},
# ... add many more comparisons ...
]
print("Collected", len(preferences), "comparisons")When you collect such data, write down your own clear guidelines first, so that your choices are consistent — exactly the discipline that distinguishes useful preference data from noise.
Summary
Preference data captures the comparative judgment that instruction tuning cannot: when two responses are both acceptable, which is better? It is collected as comparisons — a prompt, a chosen response, and a rejected one — because humans judge relative quality far more reliably than they assign absolute scores. Collection involves generating candidates and having guided human raters pick the better one, where the guidelines quietly encode the system's values along dimensions like helpfulness, honesty, and harmlessness. These comparisons become a reward signal, which is the "human feedback" in RLHF and connects directly to reinforcement learning. The process is expensive, subjective, and value-laden, which is why alignment is as much a human question as a technical one.
Both instruction and preference data are costly to gather by hand. Chapter 19 closes Part IV by examining how models themselves can help generate training data — the promise and the real perils of synthetic data.
Exercises
- 1Given a prompt of your choice, write two responses — one clearly better than the other — and record them as a (prompt, chosen, rejected) triple. Explain in one sentence why the chosen response wins.
- 2Explain why preference data uses pairwise comparisons rather than absolute scores. Give an everyday example, outside of AI, where you find comparing easier than scoring.
- 3Design a simple rating rubric a human could use to compare two assistant responses. Include at least three dimensions and a rule for what to do when they conflict.
- 4Explain the difference between an instruction dataset (Chapter 17) and a preference dataset. What does each teach a model that the other cannot?
- 5Connect preference data to reinforcement learning from Chapter 6. What plays the role of the 'reward', and why does this give rise to the name RLHF?
- 6The chapter argues that whoever writes the rating guidelines is making value-laden choices. Pick a contested kind of request and describe two reasonable but conflicting views on what the 'better' response would be.