
Chapter 28Advanced Prompting: Chain-of-Thought, Few-Shot, and Self-Consistency
With the fundamentals of clear, specific prompting in hand, we can add a few powerful techniques that push quality higher on the genuinely hard tasks — the ones involving reasoning, multi-step logic, or a precise format. These techniques are not always needed, and using them where they do not belong just wastes tokens, so we will be equally clear about *when* to use each. By the end you will know how to make a model think more carefully, learn from examples, and double-check itself, and how to tell whether any of it actually helped.
Beyond the Basics
The fundamentals from Chapter 27 handle most tasks. But some problems — careful reasoning, math, multi-step logic, or matching an exact style — benefit from more. The three techniques in this chapter are the most useful and widely applicable. The art is knowing when each helps, because each also has a cost in tokens, latency, or complexity. We will treat them in order of how often you will reach for them.
Few-Shot Prompting: Learning from Examples
We touched on this in Chapter 20 as in-context learning, and it deserves a proper look. A prompt with no examples is called zero-shot: you just describe the task. A prompt that includes a few worked examples before the real request is called few-shot. The examples teach the model the format and approach by demonstration, which is often far more effective than describing them in words.
# Few-shot: show the pattern, then ask for the next one.
prompt = (
"Turn each product into a one-line marketing tagline.\n\n"
"Product: noise-cancelling headphones\n"
"Tagline: Silence the world, hear only what matters.\n\n"
"Product: insulated water bottle\n"
"Tagline: Cold for 24 hours, ready for anything.\n\n"
"Product: ergonomic office chair\n"
"Tagline:"
)
# The two examples teach the style far better than a paragraph describing it.Use few-shot prompting when the format or style matters and is easier to show than to describe, or when a task is unusual enough that examples steer the model better than instructions alone.
How Many Examples?
Usually just a few — often one to five — is enough, which is why it is called few-shot rather than many-shot. More examples are not automatically better: they consume tokens and context, and beyond a handful the returns diminish quickly. What matters more than quantity is that your examples are correct, high-quality, and representative of the range of cases you care about, since the model imitates them closely. A few excellent, well-chosen examples beat a dozen mediocre ones.
Chain-of-Thought: Letting the Model Think
This is the most impactful technique in the chapter. Chain-of-thought prompting asks the model to reason step by step before giving its final answer, and it dramatically improves performance on reasoning, math, and multi-step problems. The trigger can be as simple as adding "Let's think step by step" or "Show your reasoning before answering."
# Without chain-of-thought, the model may jump to a wrong answer:
"A shop had 23 apples, sold 8, then received 12 more. How many now? "
"Answer with just the number."
# With chain-of-thought, it reasons first and gets it right:
"A shop had 23 apples, sold 8, then received 12 more. How many now? "
"Think step by step, then give the final number."
# -> "Start with 23. Sell 8 -> 15. Receive 12 -> 27. The answer is 27."Why Chain-of-Thought Works
The reason connects directly to how models generate text (Chapters 10 and 13). A model produces one token at a time, and each token is informed by everything written so far. When you force it to jump straight to an answer, it has to do all its reasoning invisibly in a single step — which it is bad at. When you let it write out the intermediate steps, each step becomes part of the context for the next, and the final answer is built on a foundation of explicit reasoning rather than a blind leap. In short, writing out the thinking gives the model room to think, because for a language model, thinking and writing are the same act.
When (and When Not) to Use Chain-of-Thought
Chain-of-thought shines on problems with genuine reasoning: math, logic puzzles, multi-step planning, careful analysis. It is wasteful on simple tasks — asking a model to "think step by step" before telling you the capital of France just burns tokens and time for no benefit. Reach for it when a problem has steps; skip it when the answer is a simple lookup. Be aware, too, that some modern models now reason this way by default, doing the step-by-step work internally, which can make an explicit instruction unnecessary.
Self-Consistency: Asking More Than Once
For especially hard problems, you can push reliability further with self-consistency. The idea is simple: instead of trusting a single chain-of-thought answer, you generate several independent reasoning paths (using some randomness so they differ), then take the answer that appears most often — a majority vote. If four out of five reasoning attempts arrive at the same answer, you can trust it more than any single attempt. The trade-off is cost: you are paying for several responses instead of one, so reserve self-consistency for high-stakes problems where reliability is worth the extra spend.
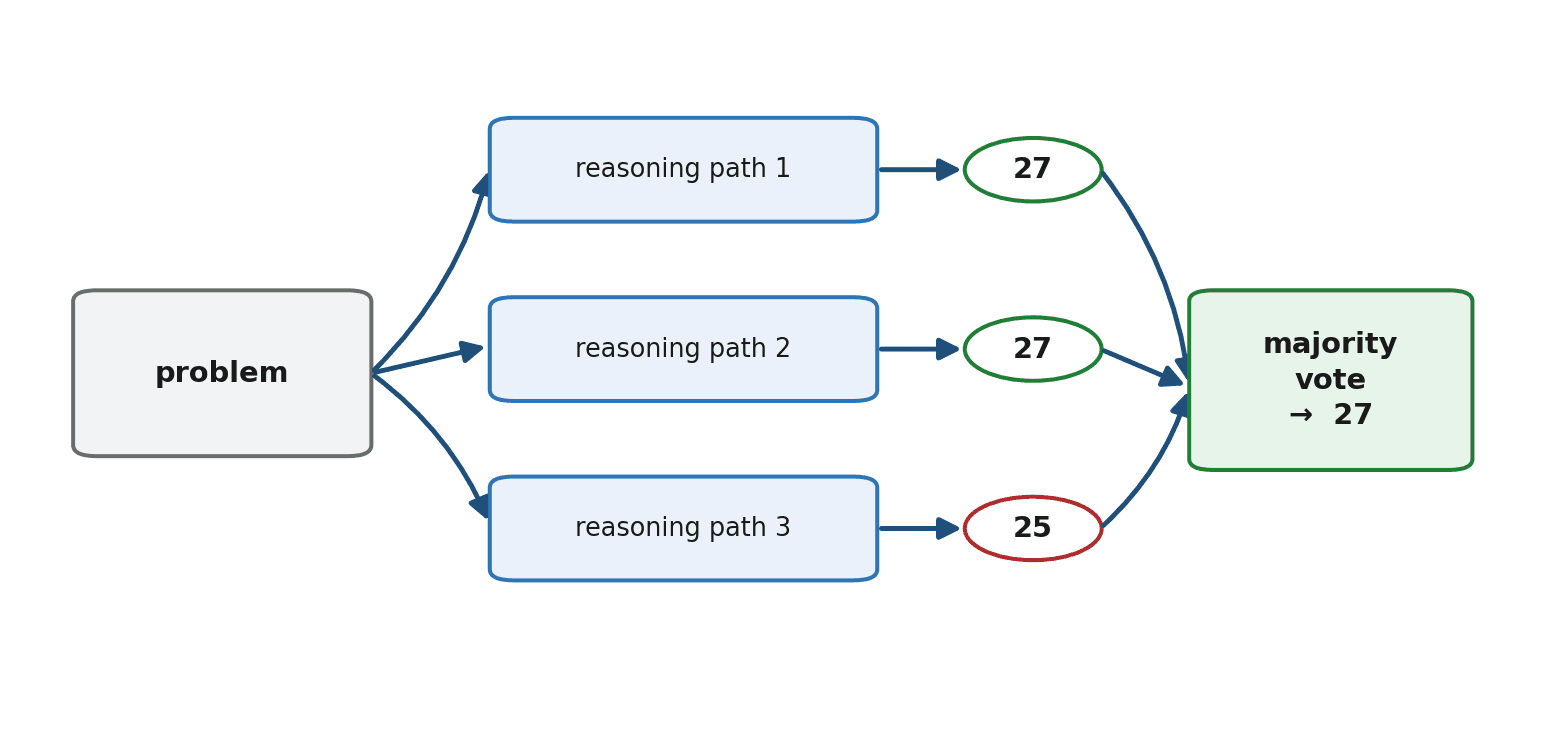
Combining Techniques
These techniques stack, with each other and with the fundamentals of Chapter 27. A common and powerful combination is few-shot plus chain-of-thought: you provide a few examples that themselves show the step-by-step reasoning, teaching the model both the format and the thinking style at once. Layered on top of a clear role, task, and constraints, these methods give you a deep toolkit for coaxing high-quality output from a model.
A Note on Evaluation
One essential caution, straight from Chapter 25: do not simply assume a technique helps. A method that improves one task may do nothing, or even hurt, on another. The only way to know is to measure — run your prompt with and without the technique against your own evaluation set and compare. This is the same verification discipline that runs through the whole book: test, do not trust your intuition. The best prompters are also diligent measurers.
Summary
Beyond the fundamentals, three advanced techniques raise quality on hard tasks. Few-shot prompting teaches by showing a few correct, representative examples, which often beats describing the task. Chain-of-thought asks the model to reason step by step before answering, dramatically helping on reasoning and math because, for a language model, writing out the thinking is what makes careful thinking possible — but it is wasteful on simple lookups. Self-consistency generates several reasoning paths and takes a majority vote, trading cost for reliability on high-stakes problems. The techniques combine with each other and the fundamentals, and you should always measure whether a technique actually helps your task rather than assuming it does.
So far our models have produced text for humans to read. To build agents, we need outputs that programs can act on, and a way for models to use tools. Chapter 29 — the technical hinge of the whole book — covers structured outputs and tool calling.
Exercises
- 1Take a multi-step reasoning problem (a word problem or logic puzzle) and ask a model to solve it first with a 'just give the answer' instruction and then with 'think step by step.' Compare the results and explain the difference.
- 2Build a few-shot prompt with three examples for a task of your choice, then test it on a new input. Now remove the examples (making it zero-shot) and compare the output quality.
- 3Explain in your own words *why* chain-of-thought improves reasoning, connecting it to how a model generates one token at a time.
- 4Give one example of a task where chain-of-thought clearly helps and one where it would just waste tokens. Justify each.
- 5Explain the idea behind self-consistency in a single paragraph, including what you trade away to gain reliability.
- 6Pick a technique from this chapter and design a small test, using an evaluation set, to measure whether it actually improves results on a task you care about. Why is measuring necessary rather than assuming?