
Chapter 36Retrieval-Augmented Generation (RAG)
A language model is a brilliant mind locked in a room with no library. It knows nothing about your company's documents, last week's meeting notes, or the PDF sitting on your desktop — and when you ask it about something it has not seen, it will sometimes invent a confident, fluent, and completely wrong answer. *Retrieval-Augmented Generation*, or RAG, is the single most important technique for fixing both problems at once. In this chapter we build a complete RAG pipeline from scratch, one stage at a time, so that you understand every moving part before any framework hides them from you.
The Problem: A Brilliant Mind With No Library
A plain language model has two limitations that matter here. First, its knowledge is frozen at the moment it was trained and contains only the public text it learned from — it has never seen your private documents and never will. Second, when it does not know something, it may hallucinate: produce a smooth, plausible, and incorrect answer. This is not lying; the model is built to continue text convincingly, not to recognize the edge of its own knowledge.
Think of the difference between a closed-book and an open-book exam. A closed-book exam tests memory and quietly rewards confident guessing. An open-book exam lets the student look up the relevant page first, then answer from it. RAG turns every question into an open-book exam: before the model answers, we find the most relevant passages from your own documents and hand them over to read.
What RAG Actually Does
RAG has two phases. The first is done once, ahead of time, to prepare your documents. The second runs every time a question is asked.
Phase one, ingestion: load your documents, cut them into bite-sized chunks, convert each chunk into an embedding, and store them. Phase two, retrieval and generation: embed the incoming question, find the stored chunks whose embeddings are most similar to it, paste those chunks into the prompt alongside the question, and let the model answer using them.
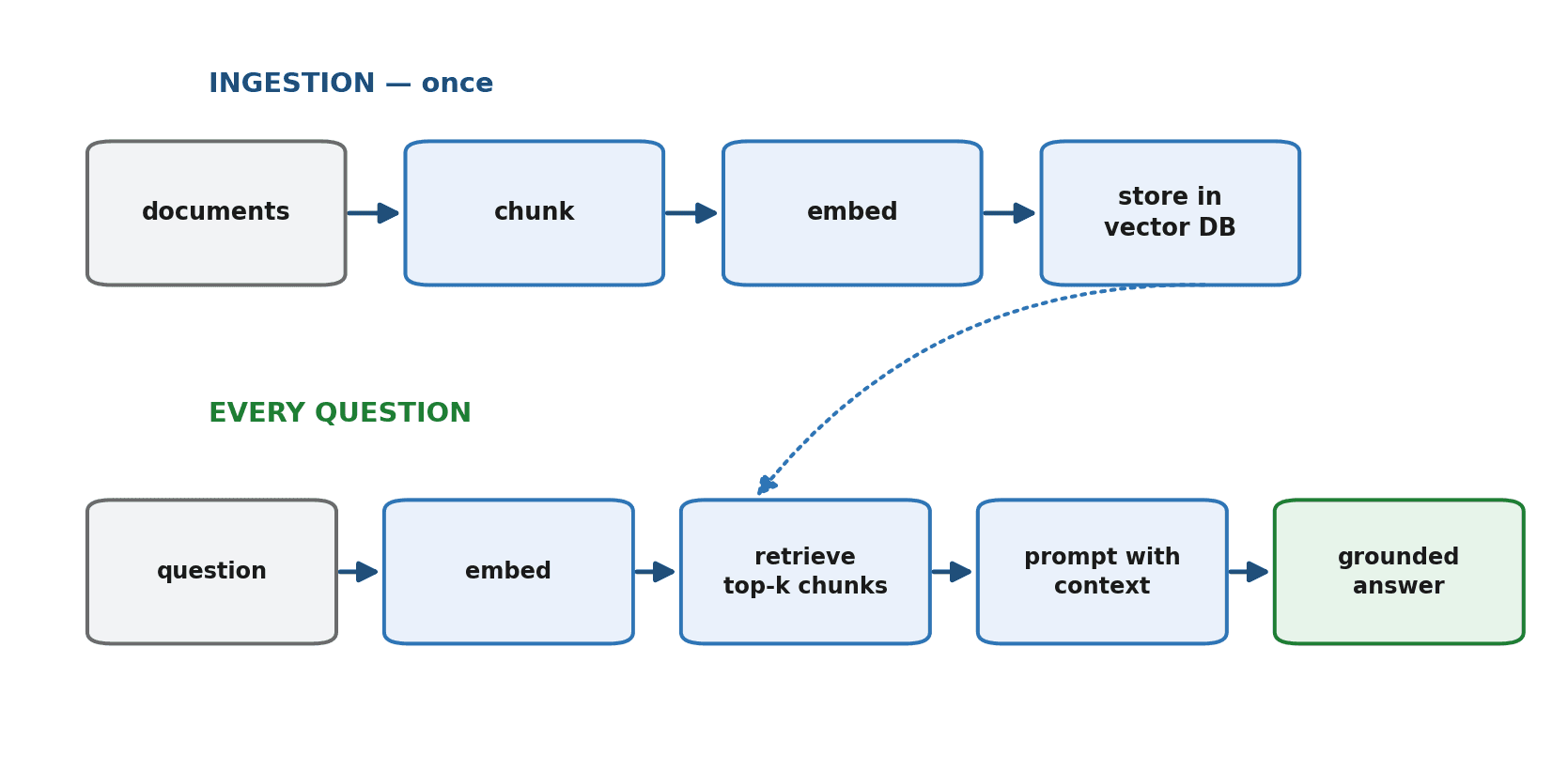
Step 1: Load Your Documents
We begin with the raw material. For a clear example we will use a handful of short passages standing in for a real knowledge base — say, the help pages of an online store.
documents = [
"Our return policy allows refunds within 30 days of purchase with a receipt.",
"Standard shipping takes 3 to 5 business days. Express shipping arrives next day.",
"The warranty covers manufacturing defects for one year from the purchase date.",
"Gift cards never expire and can be used on any product in the store.",
]In a real system you would load these from files, a database, or a website instead of typing them out. The rest of the pipeline is identical no matter where the text comes from, so this simplification costs us nothing in understanding.
Step 2: Split Documents Into Chunks
Real documents are far longer than a single sentence, so we cut them into smaller pieces called chunks. Why not just feed in whole documents? Two reasons. Retrieval is more precise when each piece covers a single idea, and the model's context window — the amount of text it can consider at once, covered in Chapter 12 — cannot hold an entire library.
Chunk size is a balancing act. Make chunks too large and a single chunk mixes several topics together, blurring retrieval so the right idea is buried among unrelated ones. Make them too small and a chunk loses the surrounding context needed to make sense on its own. A few hundred words is a common starting point, usually with a small overlap between consecutive chunks so that an idea straddling a boundary is not sliced in half.
Our toy documents are already one idea each, so each becomes its own chunk. For longer text, here is a simple splitter you can reuse:
def chunk_text(text, words_per_chunk=150, overlap=20):
words = text.split()
chunks = []
start = 0
while start < len(words):
end = start + words_per_chunk
chunks.append(" ".join(words[start:end]))
start = end - overlap # step back a little so chunks overlap
return chunksStep 3: Turn Each Chunk Into an Embedding
Now we convert every chunk into an embedding, so that later we can compare meanings mathematically. We will lean on a helper named embed() that sends text to an embedding model and returns a vector — a list of numbers representing the text's meaning.
import numpy as np
def embed(text):
# Sends text to an embedding model and returns a vector.
# The exact API differs by provider, but the idea is always the same:
# similar meanings produce similar vectors.
return embedding_model.encode(text)
chunks = documents # already one idea each
chunk_embeddings = [embed(c) for c in chunks] # embed every chunk onceStep 4: Store the Embeddings
For a few chunks, a plain list held in memory is enough — that is exactly what chunk_embeddings already is. For thousands or millions of chunks, you would instead use a vector database, which stores embeddings and finds the similar ones extremely fast. Chapter 37 is devoted to those. The logic does not change at all; only the storage scales up.
Step 5: Retrieve the Most Relevant Chunks
When a question arrives, we embed it the same way, then measure how close its embedding is to each chunk's embedding. The standard measure is cosine similarity, which scores two vectors from -1 (pointing opposite ways) to 1 (pointing the same way). A higher score means the two pieces of text are closer in meaning.
def cosine_similarity(a, b):
a, b = np.array(a), np.array(b)
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
def retrieve(question, k=2):
q = embed(question)
scored = [(cosine_similarity(q, e), c)
for c, e in zip(chunks, chunk_embeddings)]
scored.sort(reverse=True) # most similar first
return [chunk for _, chunk in scored[:k]] # keep the top k chunksThe retrieve function returns the k chunks whose meaning sits closest to the question — our "relevant pages" for the open-book exam. Choosing k is its own small art: too few and you may miss the answer, too many and you bury it in noise.
Step 6: Generate an Answer From the Retrieved Chunks
Finally we hand the retrieved chunks to the model along with the question, instructing it to answer using only what we have provided. This is the step that grounds the answer in your documents rather than in the model's imagination.
from anthropic import Anthropic
client = Anthropic()
def answer(question):
context = "\n\n".join(retrieve(question))
prompt = (
"Answer the question using ONLY the context below. "
"If the answer is not in the context, say you don't know.\n\n"
f"Context:\n{context}\n\nQuestion: {question}"
)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=300,
messages=[{"role": "user", "content": prompt}],
)
return response.content[0].textTwo instructions in that prompt do the heavy lifting. "Use ONLY the context" keeps the model from wandering off into invented territory, and "if it is not in the context, say you don't know" gives the model explicit permission to admit ignorance instead of guessing. Without that permission, a model will often fill the silence with something plausible and false.
Putting It All Together
That is a complete RAG system. Ask it a few questions and watch it ground each answer in the documents:
print(answer("How long do I have to return something?"))
# -> Uses the return-policy chunk: "within 30 days, with a receipt."
print(answer("Do gift cards expire?"))
# -> Uses the gift-card chunk: "no, they never expire."
print(answer("What is the capital of France?"))
# -> Not in the provided context, so it answers that it doesn't know.That third example is the entire point of RAG in miniature. A plain model would cheerfully answer "Paris," but our grounded system correctly reports that the answer is not in the provided documents — because we restricted it to them. In a real support assistant, that restraint is precisely what stops confident, off-topic, or wrong answers from reaching a customer.
Watching RAG Prevent a Hallucination
Suppose a customer asks, "Is there a restocking fee on returns?" Our documents say nothing about restocking fees. Asked directly, a plain model might invent a specific-sounding "15% restocking fee," simply because that phrasing is common in the text it was trained on. Our RAG system instead retrieves the return-policy chunk, finds no mention of any fee, and — following our instruction — says it does not know. The gap between an invented policy and an honest "I don't know" can be the gap between a complaint, or even a lawsuit, and a satisfied customer.
Making It Better
The pipeline you just built is complete but deliberately basic. The common ways to strengthen it, each explored later in the book, include:
- Better chunking — tune the size and overlap, or split along natural boundaries such as headings and paragraphs rather than fixed word counts.
- Retrieving more or fewer chunks — more context can help, but too much buries the answer and costs more to process.
- Adding metadata — store each chunk's source and date so that answers can cite exactly where they came from.
- Re-ranking — add a second, more careful pass that reorders the retrieved chunks before they reach the model.
- Letting the agent decide when to retrieve — covered in Chapter 43 on agentic RAG, where retrieval becomes a tool the agent chooses to use rather than a fixed step it always runs.
Summary
RAG turns a closed-book model into an open-book one. You ingest documents by loading, chunking, embedding, and storing them; you answer questions by embedding the question, retrieving the nearest chunks, and generating an answer with a strict instruction to stay grounded in what was retrieved. Crucially, you built every stage by hand — loading, chunking, cosine-similarity retrieval, and grounded generation — so the machinery holds no mystery for you.
Next, Chapter 37 scales the storage step with vector databases, and Part VIII shows how agent frameworks assemble pipelines just like this one in only a few lines of code. The difference now is that you know exactly what those few lines are really doing.
Exercises
- 1Build the RAG pipeline from this chapter. Ask it three questions whose answers are in the documents and two whose answers are not. Confirm it answers the first three correctly and declines the last two.
- 2Add two new documents of your own, then ask a question that can only be answered by combining information from two different chunks. Does retrieval surface both? If not, raise `k` and try again.
- 3Take one genuinely long document — an article you like, for instance — and run it through `chunk_text`. Print the chunks and judge whether the boundaries fall in sensible places. Adjust `words_per_chunk` and `overlap` and describe how the chunks change.
- 4Deliberately weaken the system by setting `k=1`, then ask a question whose answer is spread across two chunks. Explain what goes wrong and why.
- 5Remove the instruction "Answer using ONLY the context" from the prompt and ask a question your documents do not cover. Compare the answer with the grounded version, and write two sentences on what this reveals about hallucination.
- 6Attach a source label to each document, include that label with the retrieved context, and modify the prompt so the model cites which document its answer came from.