
Chapter 43Agentic RAG and GraphRAG
Part IX takes you to the cutting edge — the techniques and concerns that separate a hobby agent from a production-grade one. We begin where retrieval left off. The basic RAG of Chapter 36 was a fixed pipeline: embed the question, retrieve, generate. It works, but it is rigid. This chapter shows two ways retrieval grows up: **agentic RAG**, where the agent decides for itself when and how to retrieve, and **GraphRAG**, which retrieves over a web of connected facts rather than isolated chunks. Both make retrieval smarter, and both build directly on what you already know.
Beyond Basic RAG
Recall the RAG pipeline from Chapter 36: every question triggered the same fixed sequence — embed the query, retrieve the nearest chunks, stuff them into the prompt, generate an answer. That uniformity is its weakness. A simple question that the model could answer on its own still triggers a retrieval; a complex question that needs several different searches gets only one; an ambiguously worded question retrieves poorly because the query was never reformulated. Basic RAG treats every question the same way. Advanced retrieval adapts to the question instead.
Agentic RAG: Retrieval as a Decision
The core idea of agentic RAG is to stop treating retrieval as a fixed step and start treating it as a decision the agent makes. Instead of always retrieving, the agent — using the reasoning of ReAct (Chapter 32) — decides whether to retrieve at all, how to phrase the search, whether to search again with a better query, and which source to consult. Retrieval becomes a tool (Chapter 33) the agent reasons about and chooses to use, rather than a pipeline it is locked into. The agent's intelligence now guides the retrieval, not the other way around.
Why Agentic RAG Is Better
Letting the agent control retrieval lets it match its effort to the question. A simple factual question it already knows? Answer directly, no retrieval, no cost. A complex question spanning several topics? Retrieve multiple times, once per sub-topic. A vaguely worded question that returns poor results? Reformulate the query and try again. An evolving research task? Retrieve, read, reason, and retrieve again based on what was found — exactly the ReAct loop applied to search. The agent adapts its retrieval strategy to the actual need, which a fixed pipeline can never do.
Agentic RAG in Code
Implementing agentic RAG is mostly a matter of exposing retrieval as a tool and letting the agent loop decide when to call it — combining Chapter 33's tools with Chapter 36's retrieval.
# Retrieval becomes a tool the agent can choose to use -- once, many times, or not at all.
def retrieve(query, k=3):
q = embed(query)
return db.search(vector=q, top_k=k) # returns the most relevant chunks
tools = [{
"name": "retrieve",
"description": "Search the knowledge base for information relevant to a query. "
"Use when you need facts you do not already know. You may call "
"it multiple times with different queries.",
"parameters": {"query": "what to search for"},
}]
# The agent loop (Chapter 31/32) now reasons about WHEN and HOW to retrieve:
answer = run_agent("Compare our return policy with our warranty terms.", tools)
# It might retrieve "return policy", then separately "warranty terms", then answer.Notice the agent chose to retrieve twice, with two different queries, because the question compared two things — something basic RAG, with its single retrieval, would handle poorly. The agent's reasoning drove a smarter retrieval strategy.
The Trade-Off
Agentic RAG is more flexible, but flexibility costs. Each decision and each retrieval is a model call, so an agentic approach uses more calls, more money, and more time than a fixed pipeline, and its behavior is harder to predict and control. The guidance follows naturally: use basic RAG when your questions are uniform and a single retrieval suffices, and reach for agentic RAG when questions vary widely in complexity and benefit from adaptive, multi-step retrieval. As always, match the tool to the need.
GraphRAG: Retrieval Over a Knowledge Graph
Basic RAG has a second limitation, separate from rigidity: it retrieves isolated chunks. That is fine for "what is our return policy?" but poor for questions about relationships — "how are these two people connected?" or "what companies did the founders of X later join?" Such questions need facts that are linked across documents, not scattered in separate chunks. GraphRAG addresses this by building a knowledge graph from the documents: entities become nodes (people, companies, concepts) and relationships become edges (founded, joined, located-in), and retrieval happens over that connected structure.
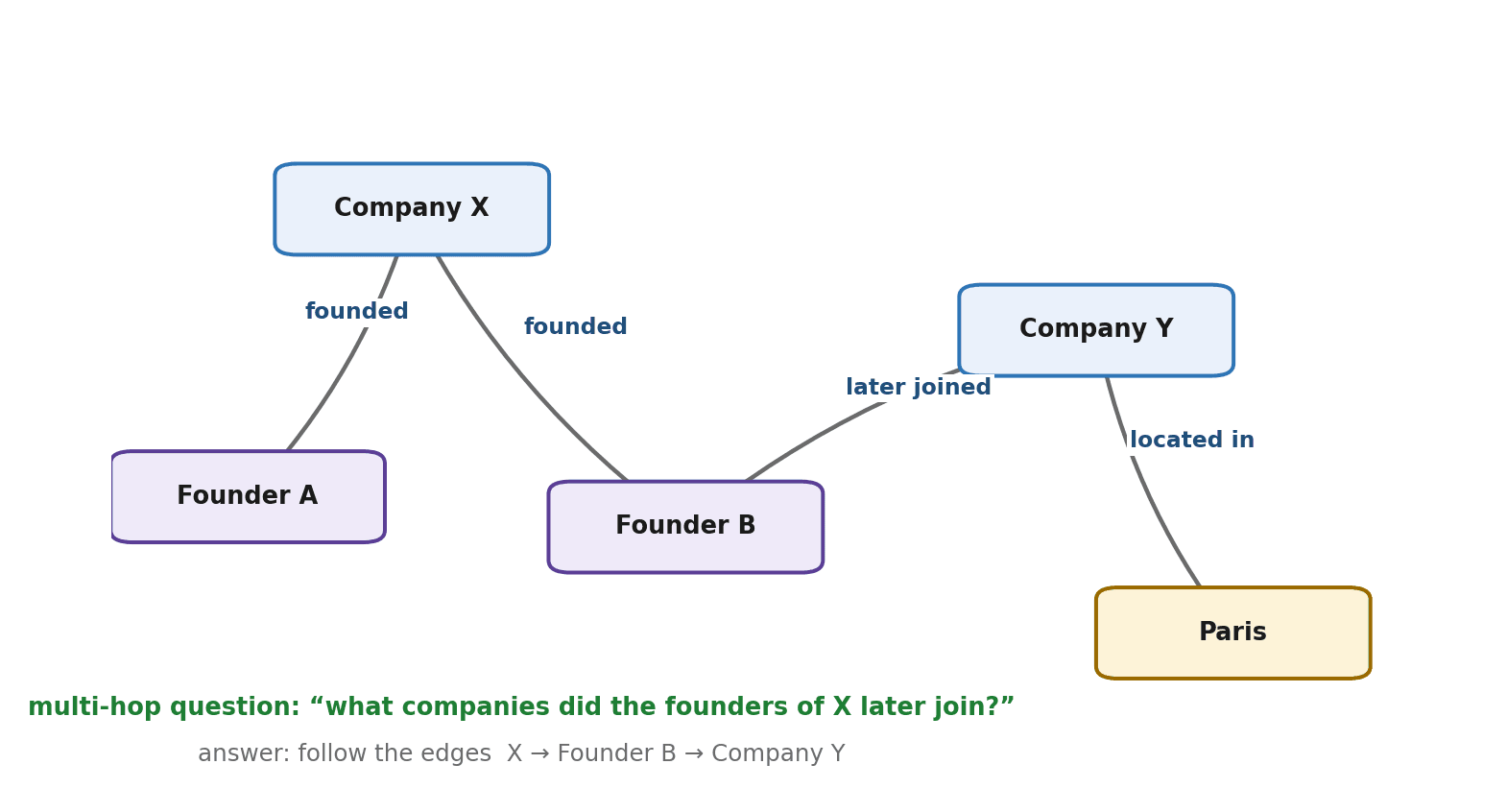
Why Graphs Help
When relationships are made explicit as edges in a graph, the system can traverse connections to answer questions that require chaining facts together — so-called multi-hop questions. To answer "what companies did the founders of X later join?", it can follow the graph from X to its founders to the companies they joined, hopping along the edges. Basic RAG, retrieving disconnected chunks, has no way to make those leaps reliably. GraphRAG also gives a more holistic view: it can summarize how a whole cluster of entities relate, rather than only surfacing the single most similar passage.
How GraphRAG Works (Conceptually)
The pipeline, at a high level, has three stages. First, extract entities and their relationships from your documents — often using a language model to read each document and pull out the people, things, and connections. Second, build these into a knowledge graph. Third, at query time, find the relevant region of the graph and reason over the connected information it contains. It is more work to build than basic RAG, but for relationship-heavy questions the payoff is answers that a flat retrieval simply cannot produce.
When to Use Each
The three approaches suit different needs, and they can be combined. Use basic RAG for straightforward fact lookup over a body of text. Use agentic RAG when questions vary in complexity and benefit from adaptive, multi-step retrieval. Use GraphRAG when questions are fundamentally about relationships and connections across your information. Many sophisticated systems blend them — an agent that decides when to retrieve, drawing on both flat and graph-based stores. Choose based on the shape of the questions you need to answer.
Retrieval Is Evolving
Retrieval is one of the most active areas of agent research, and new variations appear constantly. But notice that the principle never changes: ground the model in real, relevant information rather than letting it rely on memory and risk hallucination. The methods — flat, agentic, graph-based, and whatever comes next — are refinements of that one durable idea. If you understand the principle and the basics, each new method is a variation you can learn quickly rather than a mystery.
Summary
Basic RAG is a fixed pipeline that treats every question the same and retrieves isolated chunks. Agentic RAG makes retrieval a decision the agent reasons about — whether to retrieve, how to phrase the query, whether to search again — by exposing retrieval as a tool in the agent loop, gaining adaptability at the cost of more calls and less predictability. GraphRAG builds a knowledge graph of entities and relationships from the documents, enabling multi-hop questions about connections that flat retrieval cannot answer. Use basic RAG for simple lookup, agentic RAG for varied complexity, and GraphRAG for relationship questions, often blending them. Through it all, the durable principle is to ground the model in real information; the methods are refinements of that one idea.
Smarter retrieval makes agents more capable, but capability is worthless if you cannot tell whether the agent is actually working. Chapter 44 tackles evaluating and observing agents — how to see what a multi-step agent did and judge whether it did it well.
Exercises
- 1Explain the two limitations of basic RAG that this chapter addresses, and which advanced technique solves each.
- 2Upgrade a basic RAG system so that retrieval becomes a tool the agent decides when to use. Give it a simple question (no retrieval needed) and a complex one (multiple retrievals) and observe the difference.
- 3Explain the trade-off of agentic RAG. When is the extra flexibility worth the extra cost, and when would basic RAG be the better choice?
- 4Describe a question that GraphRAG could answer but basic RAG would struggle with, and explain why the graph structure makes the difference.
- 5Outline, in your own words, the three conceptual stages of building a GraphRAG system from a set of documents.
- 6The chapter says 'the principle outlasts the methods.' State the durable principle of retrieval in one sentence, and explain why understanding it makes new methods easy to learn.