
Chapter 5The Math You Actually Need (Intuition First)
Many people approach anything labelled "math" with a flinch, bracing for walls of symbols. This chapter asks for none of that. We are not here to prove theorems; we are here to build *intuition* — a feel — for just three ideas that quietly power everything in AI: vectors, probability, and gradients. Each comes with a picture and a tiny example, and you will never be asked to derive anything. By the end, these words will feel like friends rather than threats, and the inner workings of later chapters will click into place.
You Need Intuition, Not Proofs
In real work, libraries do all the actual calculation for you — you will almost never compute any of this by hand. What you genuinely need is the feel for what is happening underneath, so that when a model behaves a certain way, you understand why. We cover exactly three ideas, and each one connects to a part of AI you have already glimpsed: vectors (how meaning is represented, behind embeddings and RAG), probability (how models generate text), and gradients (how models learn).
Vectors: Lists of Numbers With Direction
A vector is, at heart, just a list of numbers. That really is all. The list [3, 4] is a vector. So is a list of hundreds of decimals. Nothing more mysterious than that.
But a vector also comes with a useful picture. A vector of two numbers can be drawn as an arrow on a flat page: [3, 4] means "go 3 to the right and 4 up." Three numbers place an arrow in three-dimensional space. The embeddings from Chapter 9 are simply vectors with hundreds or thousands of numbers — far too many to draw, but the idea is unchanged: a position in space whose location captures meaning.
embedding = [0.21, -0.07, 0.88, 0.13] # a (tiny) vector
print(len(embedding)) # 4 numbers = 4 dimensionsMeasuring Similarity
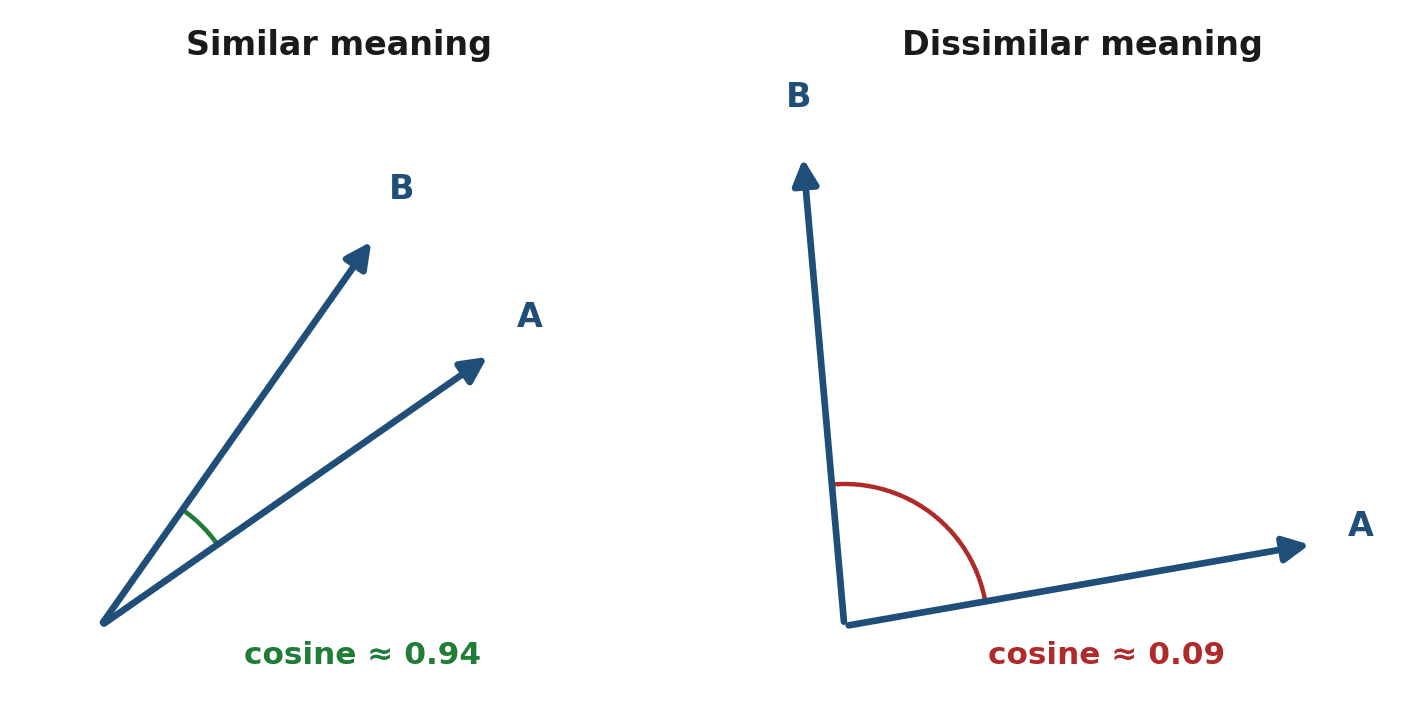
Here is why vectors matter so much for agents. If meaning is a position in space, then similar meanings sit close together, and closeness is something we can measure with a number. Two common measures are how far apart two vectors are (distance) and how much they point in the same direction (cosine similarity, which you met in Chapter 36).
Underneath much of this lies one simple operation, the dot product: multiply the two vectors entry by entry, then add up the results. For vectors of similar size, a larger dot product means they point in more similar directions.
a = [1, 2, 3]
b = [2, 1, 0]
dot = a[0]*b[0] + a[1]*b[1] + a[2]*b[2] # 1*2 + 2*1 + 3*0
print(dot) # 4Cosine similarity refines this into a tidy score from -1 to 1 by accounting for the lengths of the vectors, so it measures pure direction regardless of size. Pointing the same way scores near 1; perpendicular scores near 0; pointing opposite scores near -1. That single number is precisely how a RAG system decides which stored chunk is most relevant to your question.
Probability: Reasoning About Uncertainty
A probability is just a number between 0 and 1 measuring how likely something is: 0 means impossible, 1 means certain, 0.5 is a coin flip. The probabilities of all the possible outcomes always add up to 1, because something must happen.
This matters because language models are probabilistic at their very core. When a model predicts the next token (Chapter 10), it does not pick one word with certainty. Instead it produces a probability for every possible next token — an entire distribution. After "the color of the sky is," the token "blue" might receive 0.55, "clear" 0.20, "gray" 0.15, and so on, all summing to 1.
next_token_probs = {
"blue": 0.55,
"clear": 0.20,
"gray": 0.15,
"vast": 0.10,
} # these add up to 1.0The model then chooses from this distribution. This probabilistic nature explains two things you have surely noticed: why the same prompt can produce different answers on different runs, and why a model can sound utterly confident while being wrong. It is sampling likely continuations of text, not looking up guaranteed facts.
Temperature: Tuning the Randomness
Because generation is probabilistic, you are handed a dial that controls how adventurous the choices are. It is called temperature. At a low temperature, the model almost always takes the most likely token, giving focused, predictable, repeatable output — ideal for facts, code, and following instructions. At a high temperature, less likely tokens get more of a chance, producing varied, creative, sometimes surprising output — useful for brainstorming.
You actually met this dial already, as the variable in Chapter 4's if example. Now you know what it truly does: it gently reshapes the probability distribution before the model samples from it. Same machinery underneath, exposed as one human-friendly knob.
Gradients: Finding the Downhill Direction
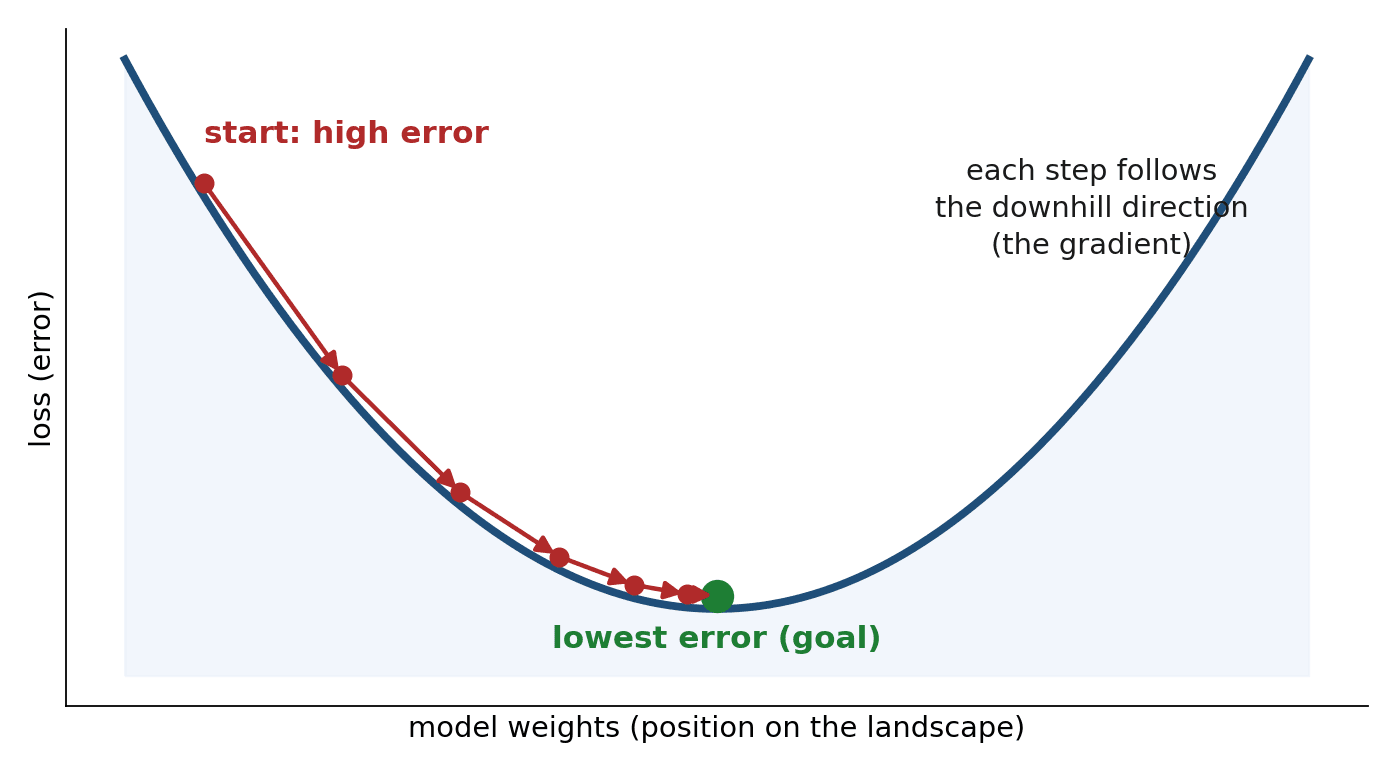
The final idea is the one behind all learning. Training a model means adjusting its millions of internal numbers so its predictions improve — that is, so its error shrinks. But with millions of knobs to turn, how could it possibly know which way to turn each one?
Picture yourself standing on a foggy hillside, wanting to reach the valley below, but able to see only the ground at your feet. A sensible plan: feel which direction slopes downhill, take a small step that way, and repeat. Do this enough times and you arrive at the bottom, even though you never saw the whole landscape.
A gradient is exactly that "which way is downhill" information, worked out for every one of the model's numbers at once. Training repeatedly nudges each number a small step in its downhill direction — the direction that reduces error. This process is called gradient descent, and despite the imposing name, it is just the foggy-hill walk, taken millions of times over. You will see it in action in Chapter 8.
Putting the Three Together
These three ideas map cleanly onto the three things a language model does, and you will meet each one again and again throughout the book.
- Vectors represent meaning — they are how text becomes numbers the model can work with, behind embeddings, search, and agent memory.
- Probability generates text — every word a model produces is a sample drawn from a probability distribution over possible next tokens.
- Gradients enable learning — training is the slow walk downhill that tunes the model's numbers to reduce its error.
That is the entire mathematical toolkit you need to begin building. Everything else in this book rests on these three intuitions, and we will deepen each of them with concrete, hands-on examples as we go.
Summary
A vector is a list of numbers with a position and direction, and closeness in that space means similarity of meaning — measured with the dot product and cosine similarity. A probability is a number from 0 to 1, and models generate text by sampling from a probability distribution over tokens, with temperature controlling how adventurous that sampling is. Gradients point downhill on the landscape of error, and learning is just repeated small steps in that downhill direction. No proofs, only pictures — which is genuinely all you need to move forward.
This completes our foundations. In Part II we put these intuitions to work, beginning in Chapter 6 with how machines learn, and building up to the neural networks and embeddings that everything else depends on.
Exercises
- 1Rewrite the vector [2, 5] as an instruction of the form "go ? to the right and ? up," then do the same for [4, 1]. Which arrow points more steeply upward, and how can you tell from the numbers?
- 2By hand, compute the dot product of [1, 0, 2] and [3, 4, 1]. Then write a few lines of code to confirm your answer.
- 3Explain to a friend, in plain language, what it means for two word embeddings to be "close together," and why that closeness is what makes a RAG system able to find relevant documents.
- 4A model's next-token probabilities are blue 0.5, green 0.3, red 0.2. Describe what a low temperature versus a high temperature would do to which word gets chosen, and say which setting you would pick when generating code that must be correct.
- 5Describe gradient descent using the foggy-hillside analogy in your own words, then state plainly what the "hill" and the "downhill direction" actually represent while a model is training.
- 6For each of the three ideas — vectors, probability, and gradients — name the part of a language model's behavior it explains. Try to do it from memory before looking back at the chapter.