
Chapter 13How LLMs Are Pretrained
We have built up, piece by piece, all the machinery of learning: neural networks, loss, gradients, the training loop. Now we put it to work at a scale that is genuinely hard to imagine, and watch how it produces a large language model. The astonishing part of this chapter is how *simple* the core idea is. An LLM learns from one deceptively humble task — predicting the next token — repeated over a quantity of text no human could read in a thousand lifetimes. Understanding pretraining clarifies the whole pipeline you set out to learn: where a model's knowledge comes from, why it sometimes invents things, and what still has to happen before a raw model becomes the helpful assistant you talk to.
From Tiny Training Loops to Giant Models
Remember the tiny training loop from Chapter 8, where a model learned a single weight by predicting, measuring its error, and stepping downhill? Pretraining is that exact loop — forward pass, compute the loss, backpropagate, update the weights — run on a model with billions of weights, over trillions of tokens, for weeks at a time. Nothing about the fundamental process is new. What is new is the scale, and the remarkable fact that scale alone transforms a simple word-guessing exercise into something that can write, reason, and code.
The One Task That Teaches Everything: Next-Token Prediction
The entire objective of pretraining is to predict the next token, given the tokens that came before. That is genuinely all. Show the model "The cat sat on the," and its job is to predict that the next token is likely "mat." Show it "The capital of France is," and its job is to predict "Paris."
Here is the elegant trick that makes this work at scale: the correct answer is already in the text. To create a training example, you take a passage, hide the next token, and ask the model to predict it — then compare its prediction to the token that was actually there. No human has to label anything; the text labels itself. This is called self-supervised learning, and it is the key that unlocked training on the entire internet, because it removed the need for armies of human labellers.
# Pretraining turns ordinary text into prediction examples automatically.
# From the sentence "The cat sat on the mat", the model practices:
examples = [
("The", "cat"),
("The cat", "sat"),
("The cat sat", "on"),
("The cat sat on", "the"),
("The cat sat on the", "mat"),
]
# In every pair, the target is just the real next token from the text itself.
# No human wrote these labels -- that is what "self-supervised" means.Why Such a Simple Task Produces Such Rich Ability
It is reasonable to be skeptical here. How could merely guessing the next word produce a system that writes essays and debugs code? The answer is one of the most beautiful ideas in the field: to predict the next token really well, across all of human writing, a model is forced to learn almost everything about that writing.
Think about what it takes to reliably predict the next token in different situations. To finish "The capital of France is ___," the model must have absorbed geography. To finish "2 plus 2 equals ___," it must have absorbed arithmetic. To finish the last line of a logical argument, it must follow the logic. To finish a sentence in fluent French, it must have learned French grammar. To finish a line of code correctly, it must have learned programming. Next-token prediction looks trivial, but doing it well secretly requires grammar, facts, reasoning, style, and far more. The simple objective is a doorway through which a vast amount of competence must pass.
Where the Data Comes From
If the task is to predict the next token across human writing, then the training data is, essentially, human writing — at enormous scale. Pretraining corpora are assembled from huge collections of text: web pages, books, articles, reference works, conversations, and large amounts of code. The totals are measured in the trillions of tokens.
But raw internet text is messy, repetitive, and full of low-quality and harmful material, so it cannot be used as-is. A great deal of careful cleaning, filtering, and deduplication goes into preparing it — which is the entire subject of Part IV of this book. For now, hold two facts: the data is vast, and its quality profoundly shapes the resulting model. A model trained on careless data learns careless patterns.
The Staggering Scale (and Why You Won't Do It Yourself)
Let us be concrete about scale, because it explains an important practical reality. A frontier model has billions of parameters — the weights from Chapter 7 — and is trained on trillions of tokens, using thousands of specialized processors running continuously for weeks or months. The electricity and hardware costs run into the millions of dollars for a single training run.
The consequence for you is liberating rather than discouraging: almost nobody pretrains a frontier model from scratch. Only a handful of well-resourced organizations do. Everyone else — including you — builds on models that have already been pretrained, accessing them through an API or downloading open ones. The hardest, most expensive part of the work has already been done and handed to you. This book teaches you to stand on top of that achievement, not to reproduce it.
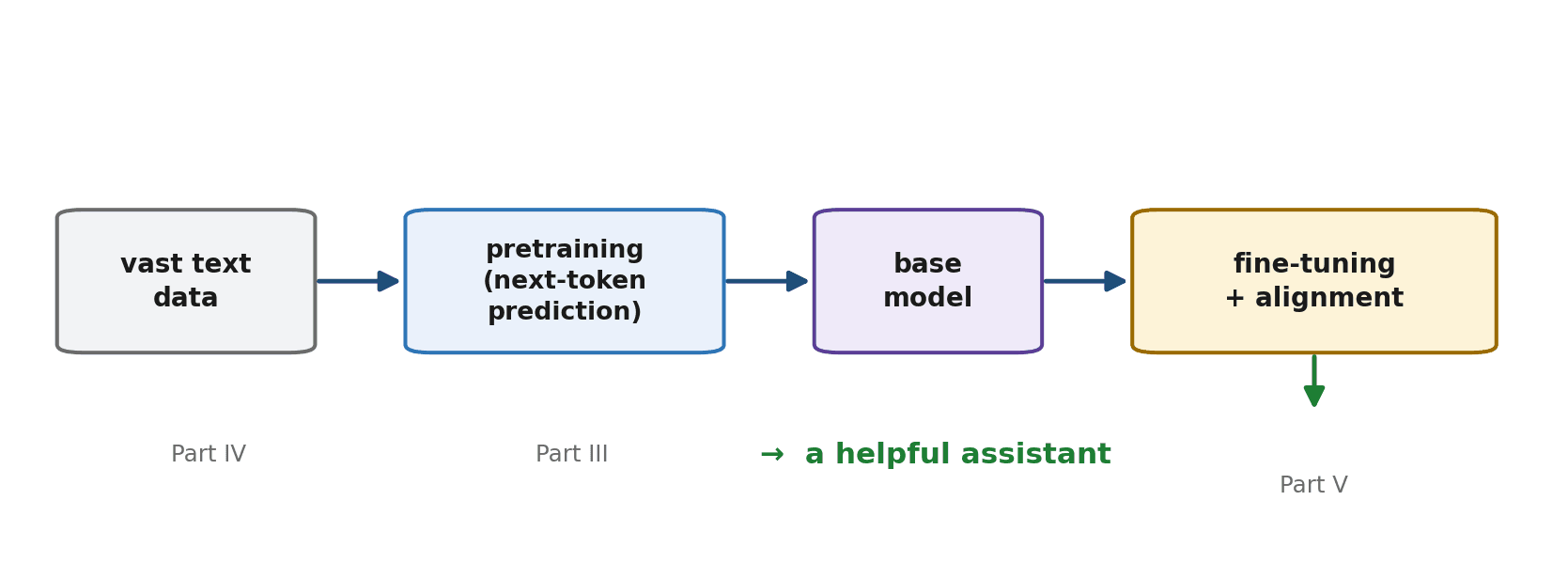
What You Get: a Base Model
After pretraining finishes, you have what is called a base model. It is a phenomenally capable text continuer — but, importantly, it is not yet the helpful assistant you are used to. A base model does exactly one thing: given some text, it continues it in a statistically plausible way. It has no special inclination to be helpful, to answer your question, or to follow your instructions. It just continues.
This leads to a famous surprise. Ask a raw base model "What is the capital of France?" and instead of answering, it might continue with more questions in the same style — "What is the capital of Italy? What is the capital of Spain?" — because that is a plausible continuation of a list of trivia questions. The base model is not being unhelpful on purpose; helpfulness was never part of its training. It learned to predict text, and that is what it does.
The Missing Steps: From Base Model to Assistant
So pretraining is only the first stage. To turn a base model into the polite, instruction-following, question-answering assistant you interact with, it goes through further training: instruction tuning, which teaches it to follow requests, and alignment methods such as learning from human feedback, which teach it to be helpful, honest, and safe. These stages are the subject of Part V.
This is the full arc you asked to understand at the very start of the book — how agentic AI works from data preparation, through training, to use. Pretraining (this chapter) gives broad knowledge; data preparation (Part IV) feeds it; fine-tuning and alignment (Part V) make it usable; and everything from Part VI onward is about using the result to build agents. You now see how the pieces connect.
Emergent Abilities, Revisited
In Chapter 2 we noted that scaling these models produced surprising new abilities that nobody explicitly built in. Now you can see the mechanism behind that mystery. As a model grows and trains on more text, its pursuit of better next-token prediction drives it to learn ever deeper structure — and at certain scales, capabilities like multi-step reasoning and instruction-following seem to appear. We still do not fully understand why these abilities emerge so suddenly, but their origin is the simple objective of this chapter, pushed to an extraordinary scale.
Summary
Pretraining is the ordinary training loop from Chapter 8, run at staggering scale on a single self-supervised task: predicting the next token. Because the correct next token is already present in the text, no human labelling is needed, which unlocked training on trillions of tokens of human writing. Predicting the next token well secretly requires grammar, facts, reasoning, and more, which is how a simple objective yields rich ability. The data is vast and its quality is decisive (Part IV). The scale is so enormous that almost no one trains frontier models from scratch — you build on pretrained ones. The result is a base model: a brilliant text continuer that is not yet a helpful assistant, which is why further fine-tuning and alignment (Part V) are needed to complete the pipeline.
We have now seen how LLMs are built. Chapter 14 closes Part III with a practical survey of the resulting landscape — hosted versus open models, and how to choose among them for your own projects.
Exercises
- 1Take a sentence of your own and write out the input-and-target pairs that pretraining would create from it, the way the chapter did for "The cat sat on the mat." Explain why no human had to label them.
- 2Explain, in your own words, how a model trained only to predict the next token could end up able to answer geography questions and write code. What is it about doing the task *well* that forces broad learning?
- 3Define self-supervised learning and explain why it was such an important enabler compared to the labelled, supervised learning of Chapter 6.
- 4Describe where pretraining data comes from and give one concrete risk that the source of the data introduces into the resulting model.
- 5Explain the difference between a base model and the assistant you normally chat with. Why might a base model respond to a question with more questions?
- 6Lay out the full pipeline from raw data to a helpful assistant in your own words, naming which part of the book covers each stage. This is the big-picture map of everything you are learning.