
Chapter 20Pretraining vs. Fine-Tuning vs. In-Context Learning
We now have prepared data and a clear picture of how models are built. Part V is about putting that data to work — training and shaping models. But before you train anything, you face a decision that can save you enormous time and money, or cost you both if you get it wrong: *which* of three very different approaches should you use to make a model do what you want? This chapter lays out pretraining, fine-tuning, and in-context learning side by side, and gives you a practical guide for choosing. Getting this choice right is one of the most valuable skills in the whole field, and beginners get it wrong constantly.
Three Ways to Make a Model Do What You Want
When you want a model to behave a certain way, you have three fundamentally different levers, distinguished by where the teaching happens. You can build knowledge into the model from scratch (pretraining). You can adjust the weights of an existing model (fine-tuning). Or you can simply tell the model what to do, right there in the prompt, with no training at all (in-context learning). They differ wildly in cost, effort, and when they make sense — so let us understand each before choosing.
Pretraining: Building From Scratch
Pretraining, which we covered in Chapter 13, is building a model's broad knowledge from the ground up: training on trillions of tokens of text to produce a base model. It is extraordinarily powerful — it is where a model's general competence comes from — but it is also extraordinarily expensive, costing millions of dollars and requiring thousands of processors running for weeks.
When should you pretrain a model from scratch? Almost never. This is the domain of a handful of well-resourced organizations. For essentially everyone else, pretraining is something you benefit from rather than do. We include it here only to complete the picture; the two approaches that follow are the ones you will actually use.
Fine-Tuning: Adjusting an Existing Model
Fine-tuning takes a model that has already been pretrained and continues training it — using the very same gradient-descent loop from Chapter 8 — on a smaller, focused dataset. This nudges the model's weights to change its behavior: to adopt a particular style, specialize in a domain, reliably produce a certain format, or follow instructions (as in Chapter 17's instruction tuning).
Because you start from an already-capable model and only adjust it, fine-tuning is far cheaper than pretraining — hours or days, not months, and a modest dataset rather than the whole internet. It permanently changes the model, baking the new behavior into its weights. We devote the next several chapters to doing it well.
In-Context Learning: Teaching in the Prompt
The third approach involves no training whatsoever. In-context learning means teaching the model what you want directly in the prompt — through instructions and examples — and letting it adapt on the spot. The model's weights never change; you simply give it the right context each time you call it. This is what "prompting," the subject of Part VI, actually is.
Remarkably, modern models are so capable that in-context learning handles a huge fraction of real tasks. You can show a model a couple of examples of the format you want and it will follow the pattern, all without a single training step.
# In-context learning: the "teaching" lives entirely in the prompt.
prompt = (
"Classify the sentiment as positive or negative.\n"
"Review: 'I loved this movie!' -> positive\n"
"Review: 'Total waste of time.' -> negative\n"
"Review: 'Best purchase I have made all year.' ->"
)
# The two examples teach the model the task on the spot. No training happened.A Decision Guide
So which should you reach for? A simple set of rules covers most situations.
- Try in-context learning first, almost always. If you can specify what you want with instructions and a few examples in the prompt, do that. It is instant, cheap, requires no data preparation, and is endlessly flexible. The overwhelming majority of tasks never need anything more.
- Fine-tune when in-context learning isn't enough. Reach for fine-tuning when you need a specific behavior consistently and at scale, when your prompt has grown huge and expensive from cramming in instructions and examples, when you need a particular style or format reliably, or when a smaller fine-tuned model could replace an expensive prompt to a larger one.
- Pretrain essentially never. Unless you are a major lab with millions to spend, build on models others have pretrained.
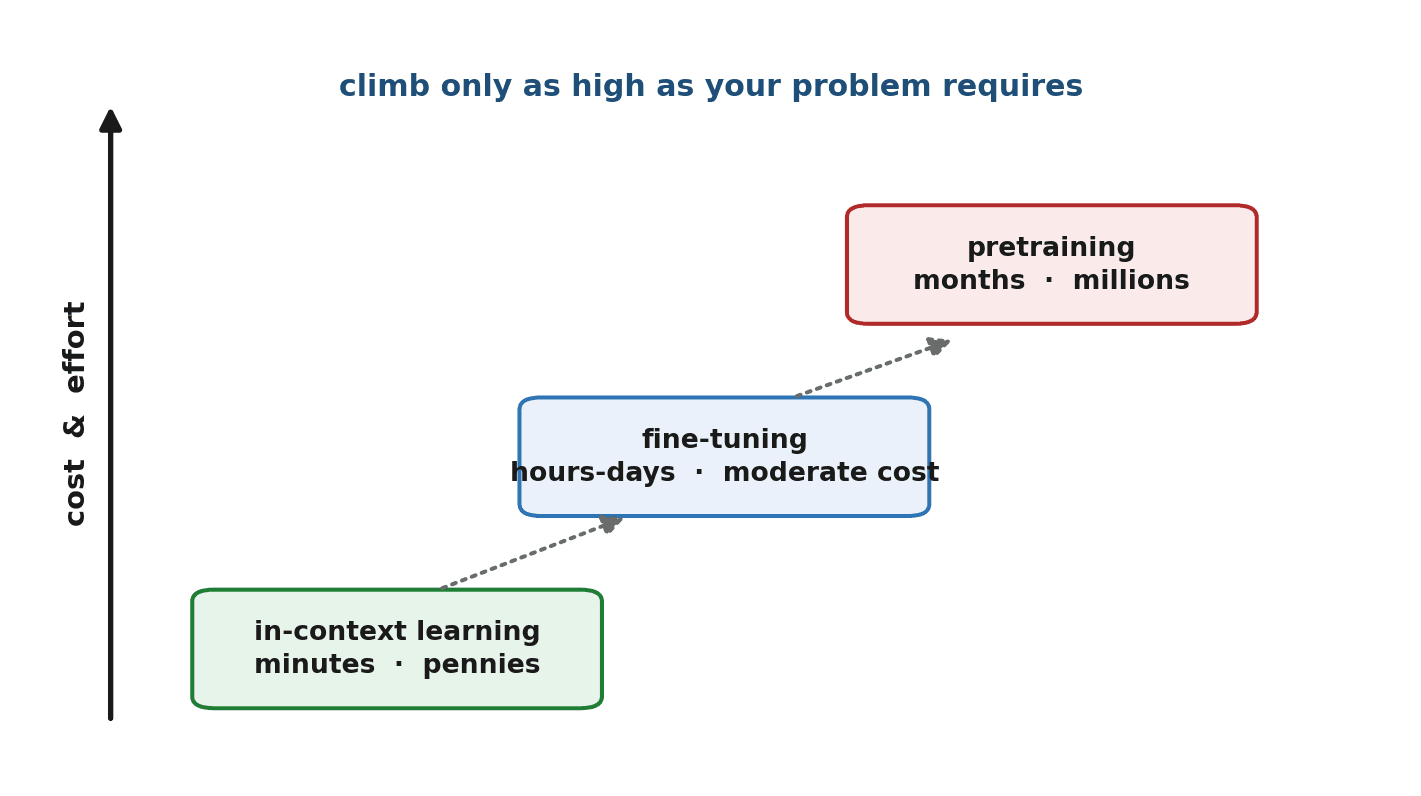
The Cost and Effort Ladder
Picture the three approaches as rungs on a ladder of cost and effort. In-context learning sits at the bottom: minutes of work, pennies per use, no data needed. Fine-tuning is the middle rung: hours or days, a prepared dataset, moderate cost. Pretraining is the top: months, vast data, millions of dollars. The guiding principle is simple — climb only as high as your problem requires. Most problems are solved on the bottom rung, and reaching for a higher one than you need wastes time and money.
They Combine
These approaches are not mutually exclusive — in fact they stack. A frontier assistant is a pretrained base model that was fine-tuned to follow instructions, which you then steer further with in-context learning every time you write a prompt. Each layer builds on the one below. Understanding this layering helps you see that choosing fine-tuning does not mean abandoning prompting; you will still prompt your fine-tuned model.
A Common Beginner Mistake
The single most common error newcomers make is reaching for fine-tuning when a better prompt would have solved the problem in minutes. Fine-tuning feels more "serious," so people assume it is the answer. Usually it is not. Before you ever prepare a dataset and spin up training, ask: could I get this behavior with a clearer prompt and a couple of examples? Far more often than not, you can.
Summary
There are three ways to make a model do what you want, differing in where the teaching happens. Pretraining builds broad knowledge from scratch at enormous cost — something you benefit from but will essentially never do yourself. Fine-tuning adjusts an existing model's weights on a focused dataset to change its behavior, at moderate cost. In-context learning teaches the model in the prompt with no training at all, and is the cheapest, fastest, and most flexible option. Try in-context learning first for almost everything, fine-tune when you need consistent specialized behavior at scale, and remember that the approaches stack. Above all, do not reach for fine-tuning when a better prompt would do, and use retrieval rather than fine-tuning to give a model new facts.
Having chosen fine-tuning when it is the right tool, Chapter 21 walks through actually doing it — fine-tuning your first model, end to end, from data to a working result.
Exercises
- 1For each scenario, choose pretraining, fine-tuning, or in-context learning and justify it: making a model reliably answer in a fixed JSON format across millions of calls; getting a one-off summary of a document in a particular tone; building a brand-new model for a language with no existing models.
- 2Explain, in your own words, why in-context learning requires no training at all. Where does the 'teaching' actually live?
- 3Rank the three approaches by cost and effort, and for each give a rough sense of the time and resources involved. Why is 'climb only as high as you need' good advice?
- 4A colleague wants to fine-tune a model so it knows their company's latest pricing. Explain why this is probably the wrong tool, and what you would recommend instead.
- 5Describe how the three approaches stack together in a typical modern assistant. What does each layer contribute?
- 6Take a task you would like to accomplish with a model. First try to solve it with in-context learning (a prompt plus examples). Only if that genuinely falls short, describe what a fine-tuning dataset for it would contain.