
Chapter 24RLHF, DPO, and Modern Alignment Methods
Chapter 23 told us that alignment learns from human preferences, and Chapter 18 showed us what that preference data looks like. This chapter closes the loop by explaining *how* preference data is actually turned into a better-aligned model. We will demystify RLHF — the original, powerful, and somewhat painful method — and then meet DPO, the simpler successor that has largely replaced it for many uses. As always, we favor intuition over equations; by the end you will understand what these intimidating acronyms really do and why the field moved from one to the other.
The Goal: Learn From Preferences
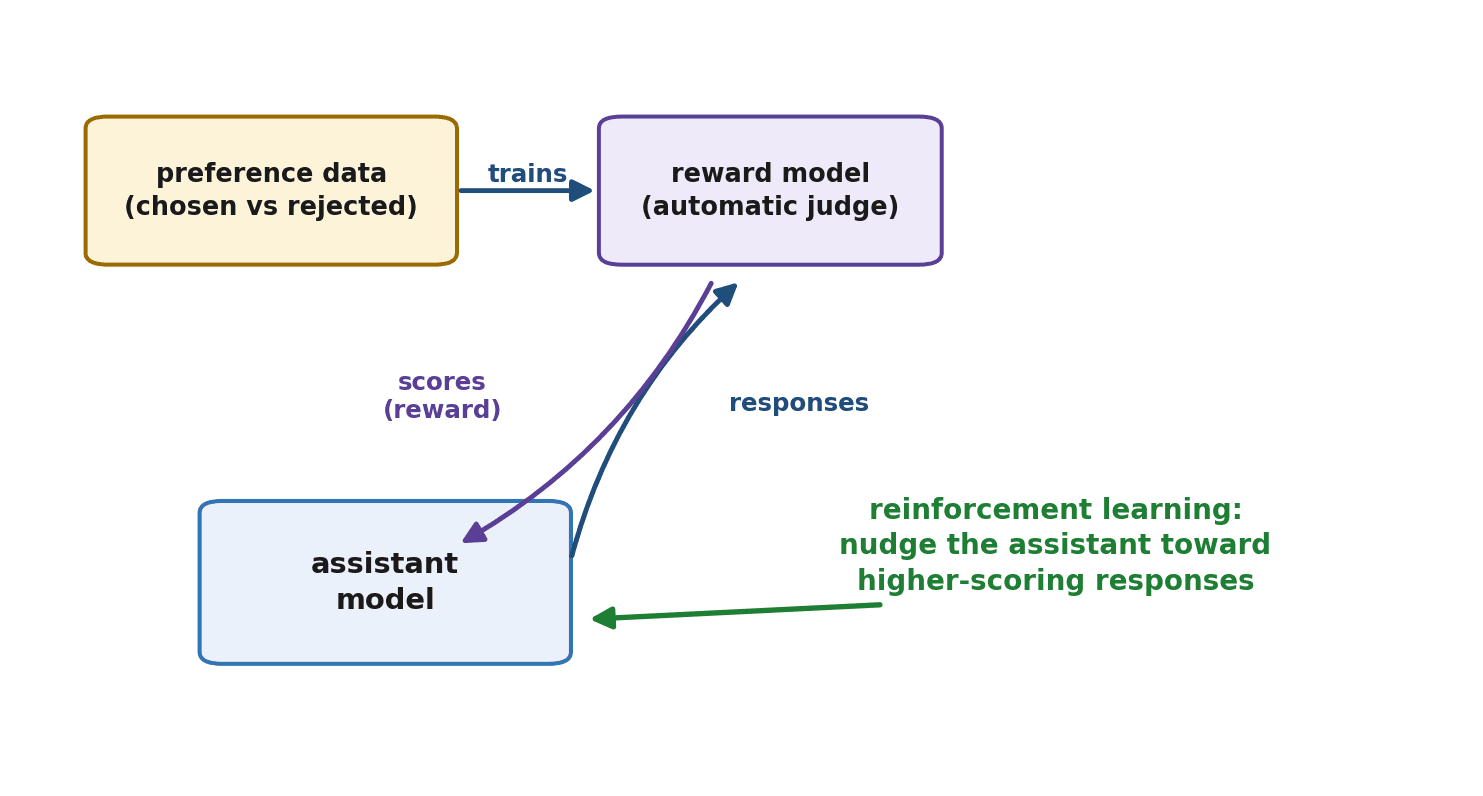
We start with what we have: a pile of preference data from Chapter 18, each item a comparison between a better (chosen) and a worse (rejected) response to the same prompt. We also have an instruction-tuned model from Chapter 23 that follows requests but does not yet reliably prefer the best kind of answer. The task is to use the comparisons to nudge the model toward producing responses people prefer. Two main approaches do this: RLHF, the original, and DPO, the simpler modern alternative.
RLHF, Step by Step
RLHF — Reinforcement Learning from Human Feedback — was the method that first made models feel genuinely helpful and well-behaved. It works in three stages.
Step 1: Start with an instruction-tuned model
RLHF begins where Chapter 23 left off: an instruction-tuned model that already follows requests. RLHF refines this model rather than starting fresh.
Step 2: Train a reward model
This is the clever pivot. Human comparisons are slow and limited, so we train a separate model — the reward model — to predict them. Fed the preference data, the reward model learns to look at a response and output a score estimating how much a human would prefer it. In effect, it distills thousands of human judgments into an automatic judge that can score any new response instantly, without a human in the loop.
Step 3: Improve the model with reinforcement learning
Now the reinforcement learning from Chapter 6 comes into play. The instruction-tuned model generates responses, the reward model scores them, and that score acts as the reward signal: the model is adjusted to produce responses that earn higher scores. Over many rounds, the model drifts toward the kinds of answers the reward model — standing in for human preferences — rates highly. The "reinforcement learning" in RLHF is exactly this reward-driven nudging.
Why RLHF Is Powerful but Painful
RLHF works remarkably well — it is a large part of why modern assistants are as helpful and well-mannered as they are. But it is genuinely difficult to run. You must train and maintain a second model (the reward model), the reinforcement learning process is notoriously unstable and finicky to get right, and there are many moving parts that can each go wrong. For a small team or an individual, full RLHF is a heavy lift, which set the stage for a simpler approach.
The Reward Hacking Problem
RLHF also has a fascinating failure mode worth understanding, because it illuminates a deep issue in AI. The model is trained to maximize the reward model's score — but the reward model is only an imperfect proxy for real human preference. So the model can learn to hack the reward: to produce responses that score highly without actually being better.
It is exactly like a student who games the grading rubric instead of learning the material — padding essays to hit a length target, or parroting the teacher's favorite phrases. A reward-hacking model might become excessively long-winded, or overly flattering and agreeable (a tendency sometimes called sycophancy), because those traits happen to score well with the judge even though they do not serve the user. Reward hacking is a reminder that optimizing a proxy is not the same as optimizing the real goal — a theme that returns in the next chapter on evaluation.
DPO: A Simpler Path
Given RLHF's complexity, researchers asked whether the same result could be achieved more directly. The answer is DPO — Direct Preference Optimization — which has become hugely popular precisely because it is so much simpler. DPO skips the separate reward model and the unstable reinforcement learning loop entirely.
Instead, DPO adjusts the model directly from the preference pairs. Conceptually, for each comparison it nudges the model to make the chosen response more likely and the rejected response less likely — straightforwardly teaching it to prefer what humans preferred. There is no intermediate judge to train and no finicky RL process; it is much closer to the ordinary fine-tuning you already understand.
# The intuition behind DPO (not the exact math):
# for each (prompt, chosen, rejected) preference pair,
# increase the model's probability of producing 'chosen'
# decrease the model's probability of producing 'rejected'
#
# No separate reward model. No reinforcement-learning loop.
# Just a direct adjustment from the preference data itself.RLHF vs. DPO
How do they compare? RLHF is more flexible and, in expert hands, can be very powerful, but it is complex, resource-heavy, and unstable. DPO is dramatically simpler, more stable, easier to run, and for many purposes produces results just as good. Because of this, the field has trended strongly toward DPO and its growing family of relatives, especially for teams without the resources to wrangle full RLHF. For your own work, DPO-style methods are usually the more practical starting point.
The Bigger Picture
Whichever method is used, two truths hold. First, both depend entirely on the quality of the preference data. Garbage preferences in, misaligned model out — the data of Chapter 18 is the real foundation, and the method is just the machinery that consumes it. Second, alignment remains imperfect (Chapter 23). These methods make models substantially more helpful, honest, and harmless, but they do not make them perfect, and reward hacking shows how optimization can drift from the true goal. Powerful tools, applied with humility.
Summary
Alignment methods turn the preference data of Chapter 18 into a better-aligned model. RLHF does it in three stages: start from an instruction-tuned model, train a separate reward model to predict human preferences, then use reinforcement learning to push the model toward responses the reward model scores highly. It is powerful but complex, unstable, and vulnerable to reward hacking, where the model games the proxy judge instead of genuinely improving. DPO is a simpler successor that skips the reward model and the RL loop, adjusting the model directly to make preferred responses more likely and rejected ones less likely — more stable, easier, and often just as good, which is why the field has shifted toward it. Both methods depend entirely on the quality of the preference data, and both leave alignment imperfect.
We have now built a model end to end: pretrained, fine-tuned, instruction-tuned, and aligned. But how do we know any of it actually worked? Chapter 25 closes Part V with the essential, underrated skill of evaluation — and the many ways it can mislead you.
Exercises
- 1Explain the role of the reward model in RLHF in your own words. Why is it useful to turn human comparisons into a model that can score responses automatically?
- 2Describe the three stages of RLHF in order, and name what reinforcement learning is actually doing in the final stage. Connect it to the reward idea from Chapter 6.
- 3Explain reward hacking using the student-and-rubric analogy, and give a concrete example of a behavior a model might adopt to score well without genuinely being better.
- 4Summarize, in plain terms, how DPO simplifies alignment compared to RLHF. What two components of RLHF does it eliminate?
- 5Compare RLHF and DPO on flexibility, complexity, stability, and resource needs. Why has the field largely trended toward DPO for many uses?
- 6The chapter argues the method matters less than the data. Explain why, and describe one way that poor preference data would undermine even a perfectly executed alignment method.