
Chapter 23Instruction Tuning and Alignment
We have the tools to fine-tune a model. Now we turn to the two-stage process that uses those tools to accomplish something specific and important: transforming a raw base model — a mere text continuer — into the helpful, honest, well-behaved assistant you actually want to interact with. Chapter 17 covered the *data* for this; here we cover the *process* and the deeper idea behind it, called alignment. This is the stage that makes a model usable and safe, and understanding it clarifies both what today's assistants are and why they sometimes behave as they do.
Recap: From Base Model to Assistant
Recall the cliffhanger from Chapter 13. After pretraining, you have a base model: astonishingly knowledgeable, but not an assistant. It only continues text, so asked "What is the capital of France?" it might reply with more trivia questions rather than an answer. Turning this into the assistant you know takes two further stages of training: instruction tuning, then alignment. This chapter covers both at the level of what they do and why; the specific alignment methods come in Chapter 24.
Instruction Tuning: Teaching the Model to Follow
The first stage, instruction tuning (also called supervised fine-tuning), is exactly the fine-tuning from Chapters 21 and 22 applied to the instruction–response data from Chapter 17. You show the base model thousands of examples of instructions paired with excellent responses, and it learns to follow requests rather than merely continue text.
The change is dramatic and immediate. The very same prompt produces completely different behavior before and after.
# Prompt: "What is the capital of France?"
# BASE model (only continues text) might produce:
# "What is the capital of Italy? What is the capital of Spain? ..."
# INSTRUCTION-TUNED model produces:
# "The capital of France is Paris."
# Same knowledge inside -- instruction tuning changed the behavior, not the facts.What Instruction Tuning Changes
It is important to see what this stage does and does not do. Instruction tuning adds little new knowledge — the model already learned its facts during pretraining. What it changes is behavior: the model now answers questions, follows formatting requests, adopts a helpful assistant persona, and stays on task. It is teaching a new way of responding, not new things to know, which is exactly why, as we saw in Chapter 17, a few thousand good examples can accomplish so much.
What "Alignment" Means
Instruction tuning makes a model follow instructions. But following instructions is not enough — we want a model that follows them well, in keeping with human values and intentions. That broader goal is called alignment: making the model's behavior match what people actually want, usually summarized as being helpful, honest, and harmless (the three pillars from Chapter 18).
Alignment goes beyond mere obedience. An aligned model is helpful when it can be, truthful rather than confidently fabricating, and unwilling to cause harm even when asked. A model that did whatever it was told, including harmful things, would be obedient but badly misaligned. Alignment is about the model wanting — in the loose sense that its training instills — the right things.
Why Instruction Tuning Isn't Enough
Why add a second stage? Because instruction tuning has a built-in limit. It teaches from single "correct" responses, which works when there is one right answer but falls short for the subtler judgments that define a good assistant. It cannot easily capture that, among several acceptable answers, one is more helpful or better phrased; and it does not reliably resolve the tensions between being helpful, honest, and harmless. Those nuances live in preferences between responses — which is precisely the preference data of Chapter 18, and the alignment methods of Chapter 24 that learn from it.
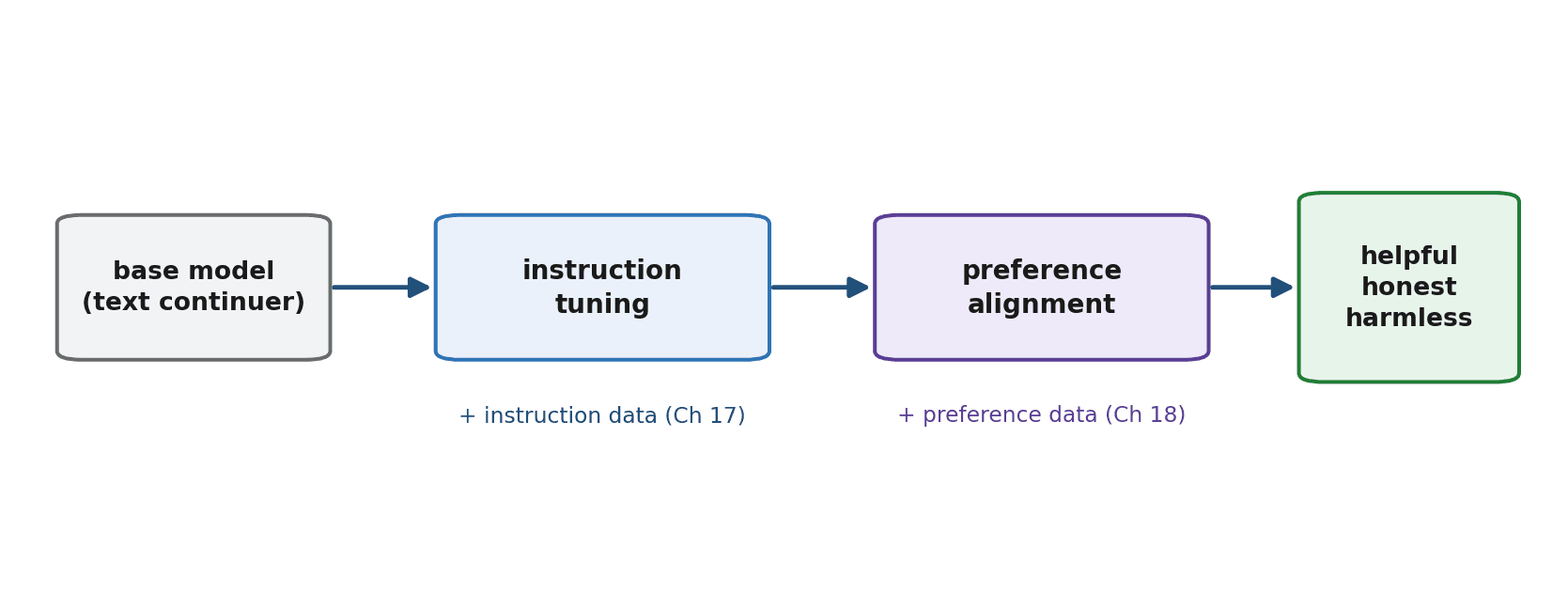
The Alignment Pipeline
Putting it together gives the canonical pipeline that produces a modern assistant — often called post-training, because it happens after pretraining.
- Pretraining (Chapter 13) — the base model learns broad knowledge and language from vast text.
- Instruction tuning (this chapter, Chapter 17) — supervised fine-tuning on instruction–response pairs teaches the model to follow requests.
- Preference-based alignment (Chapters 18 and 24) — learning from human preferences refines the model to be more helpful, honest, and harmless.
Each stage builds on the one before. Pretraining provides the raw capability; instruction tuning shapes it into a follower of instructions; alignment polishes it into a genuinely good assistant. This is the arc from raw model to the thing you chat with.
The Three Pillars: Helpful, Honest, Harmless
The aims of alignment are usually summarized as three pillars, and the interesting part is how they pull against one another.
- Helpful — the model genuinely addresses the request and does useful work, rather than dodging or giving empty non-answers.
- Honest — the model tells the truth as best it can, acknowledges uncertainty, and does not fabricate facts with false confidence.
- Harmless — the model avoids causing harm, declining requests that would hurt people even when a literal-minded "helpful" model might comply.
These three are in constant tension. The most helpful response to a dangerous request would be harmful. The most cautious, harmless response can be unhelpfully evasive. A model that always sounds confident may seem helpful while being dishonest. Much of alignment is teaching a model to navigate these trade-offs the way thoughtful humans would — and reasonable people sometimes disagree about the right balance, which is why this is genuinely hard.
Alignment Is Ongoing and Imperfect
It is important to be honest: no model is perfectly aligned. Values are contested (a theme from Chapter 18), the tensions above have no universally agreed resolution, and models can still be coaxed into unhelpful or unsafe behavior. Alignment is not a box that gets ticked once; it is continual work and one of the most active and important open problems in the entire field. Treating any model as flawlessly safe or perfectly truthful is a mistake.
Why This Matters for Agents
For agents, alignment is not academic — it is safety-critical. A misaligned chatbot might say something wrong; a misaligned agent might do something wrong, because agents take actions in the world (Chapter 1). A model that can send emails, run code, or move money inherits all of alignment's imperfections, and the stakes of those imperfections rise sharply. This is why Part IX devotes a full chapter to guardrails and safety, and why understanding alignment now will make you a more responsible agent builder later.
Summary
Turning a base model into a helpful assistant takes two stages beyond pretraining. Instruction tuning — supervised fine-tuning on instruction–response pairs — teaches the model to follow requests rather than merely continue text, changing behavior rather than adding knowledge. Alignment is the broader goal of making the model's behavior match human values, summarized as helpful, honest, and harmless, three pillars that pull against each other. Instruction tuning alone cannot capture the nuanced preferences and trade-offs that define a good assistant, so preference-based alignment is added on top, completing the pretraining → instruction-tuning → alignment pipeline. Alignment is ongoing and imperfect, which matters enormously once a model is given the power to act as an agent.
We have said alignment learns from preferences but deferred how. Chapter 24 fills that gap, demystifying RLHF and the simpler modern methods like DPO that turn preference data into a better-aligned model.
Exercises
- 1Explain the difference between a base model and an instruction-tuned model. Give a concrete example, like the capital-of-France one, of how their responses to the same prompt differ.
- 2In your own words, define alignment and explain how it is more than just 'following instructions'. Give an example of a model that is obedient but misaligned.
- 3Describe the three-stage post-training pipeline and what each stage contributes. Why must they happen in that order?
- 4Pick a single request and describe how the helpful, honest, and harmless pillars might pull in different directions when responding to it. How would a well-aligned model balance them?
- 5If you can access both a base model and an instruction-tuned version (many open model families offer both), give them the same prompt and compare the responses. Describe the difference in behavior.
- 6Explain why alignment matters even more for agents than for chatbots. Connect your answer to the idea that agents take actions.