
Chapter 7Neural Networks from Scratch (The Intuition + a Tiny Build)
"Neural network" is one of those phrases that sounds like it requires a doctorate to understand. It does not. By the end of this chapter you will know exactly what a neural network is, because you will have built the smallest possible one yourself, in a few lines of code. The secret, which the intimidating name hides, is that a neural network is just numbers, multiplication, addition, and one simple bend — repeated many times. We build it from a single piece and assemble upward, so nothing is ever mysterious.
The Big Fear, Defused
The name conjures images of an artificial brain, and the brain inspiration is real but loose. What a neural network actually does is far more modest and far more graspable: it takes some numbers in, multiplies and adds them in a particular way, bends the result slightly, and passes numbers out. Stack enough of these simple steps and the whole thing can recognize faces or write text — but each individual step is something a schoolchild could compute. Let us meet that step.
The Neuron: The Basic Unit
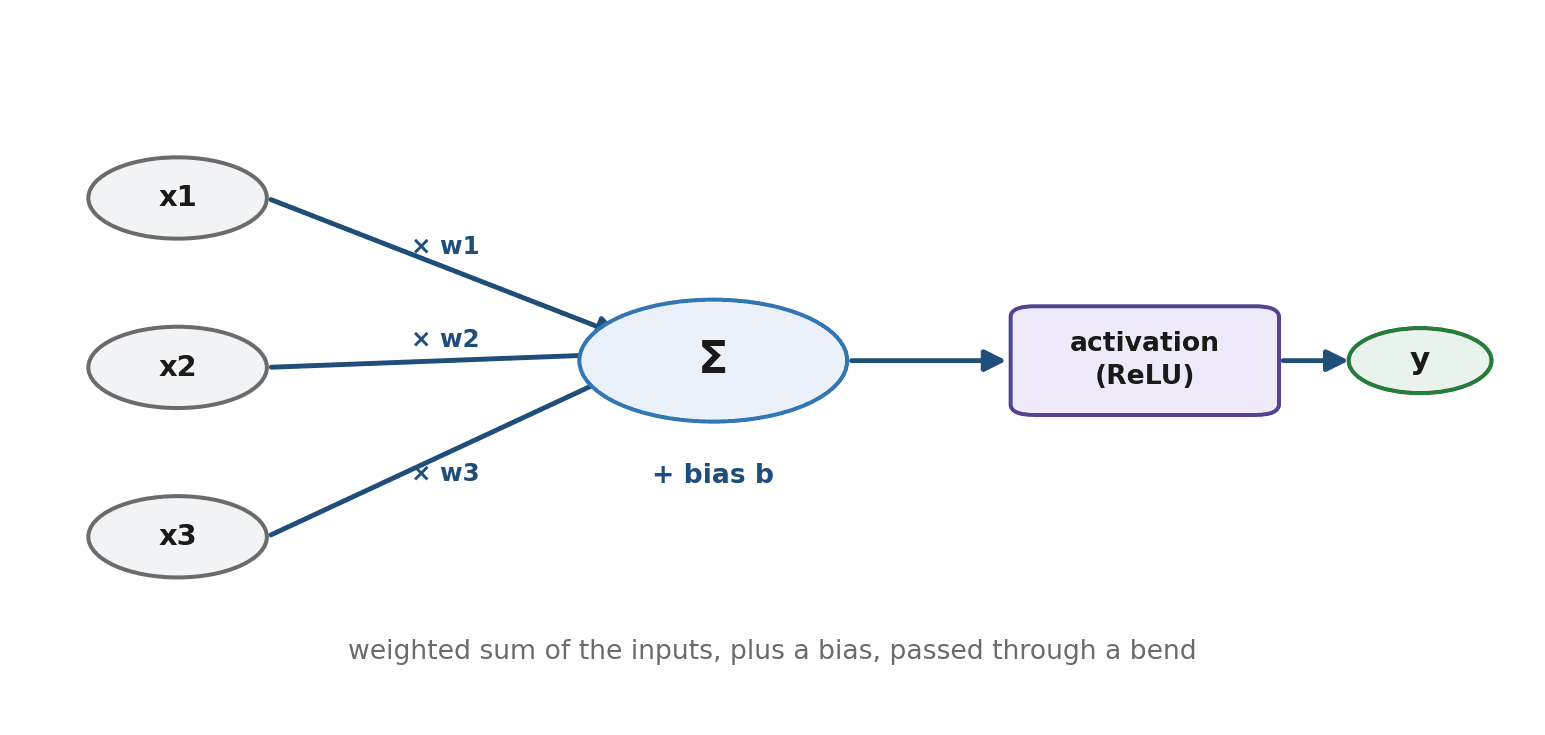
The building block of every neural network is the neuron (sometimes called a node). A single neuron does four small things in order: it takes several input numbers, multiplies each input by its own weight, adds all those products together along with an extra number called a bias, and finally passes the total through an activation function that bends it.
Think of a neuron as a tiny voting machine weighing evidence. Each input is a piece of evidence; each weight is how much that evidence matters; the bias tilts the decision one way or the other; and the activation function decides how strongly the neuron "fires" given the total. A weight of zero means "ignore this input entirely"; a large weight means "this input matters a lot."
Building a Neuron in Code
Words are one thing; let us make it real. First the activation function. We will use the most common one, called ReLU, which is almost comically simple: if the number is negative, it becomes zero; otherwise it stays as it is.
def relu(x):
return max(0, x) # negatives become 0; positives stay the sameNow the neuron itself. It takes a list of inputs and a matching list of weights, multiplies them pair by pair, adds the bias, and applies the activation.
def neuron(inputs, weights, bias):
total = bias
for x, w in zip(inputs, weights):
total += x * w # weighted sum of the evidence
return relu(total) # bend the result
# Try it with two inputs
output = neuron(inputs=[1.0, 2.0], weights=[0.5, -1.0], bias=0.5)
print(output) # relu(1*0.5 + 2*-1.0 + 0.5) = relu(-1.0) = 0That is a complete artificial neuron. Read the arithmetic in the comment and you can see there is no magic at all — just multiply, add, and bend. Every giant model you have heard of is made of millions of units doing exactly this.
Why the Activation Function?
That little bend is more important than it looks. Without an activation function, a neuron would only ever compute a weighted sum — a straight-line relationship. And here is the catch: stacking straight lines on top of straight lines just gives you another straight line. No matter how many layers you piled up, the whole network could only ever draw a straight line, which is far too simple to capture the messy, curved patterns of the real world.
The activation function introduces a non-linearity — a bend — and that bend is what lets networks learn curves, corners, and complexity. With non-linear activations between them, stacked layers can approximate astonishingly intricate patterns. The simple bend is what turns a pile of multiplication into something powerful.
From One Neuron to a Layer
A single neuron looks for one pattern. Put several neurons side by side, each with its own weights, and you get a layer — a team of neurons all examining the same inputs but each looking for something different. One might respond to one combination of inputs, another to a different combination.
def layer(inputs, list_of_weights, biases):
# one output per neuron in the layer
return [neuron(inputs, w, b)
for w, b in zip(list_of_weights, biases)]
outputs = layer(
inputs=[1.0, 2.0],
list_of_weights=[[0.5, -1.0], [1.0, 1.0]], # two neurons
biases=[0.5, 0.0],
)
print(outputs) # one number from each neuronFrom Layers to a Network
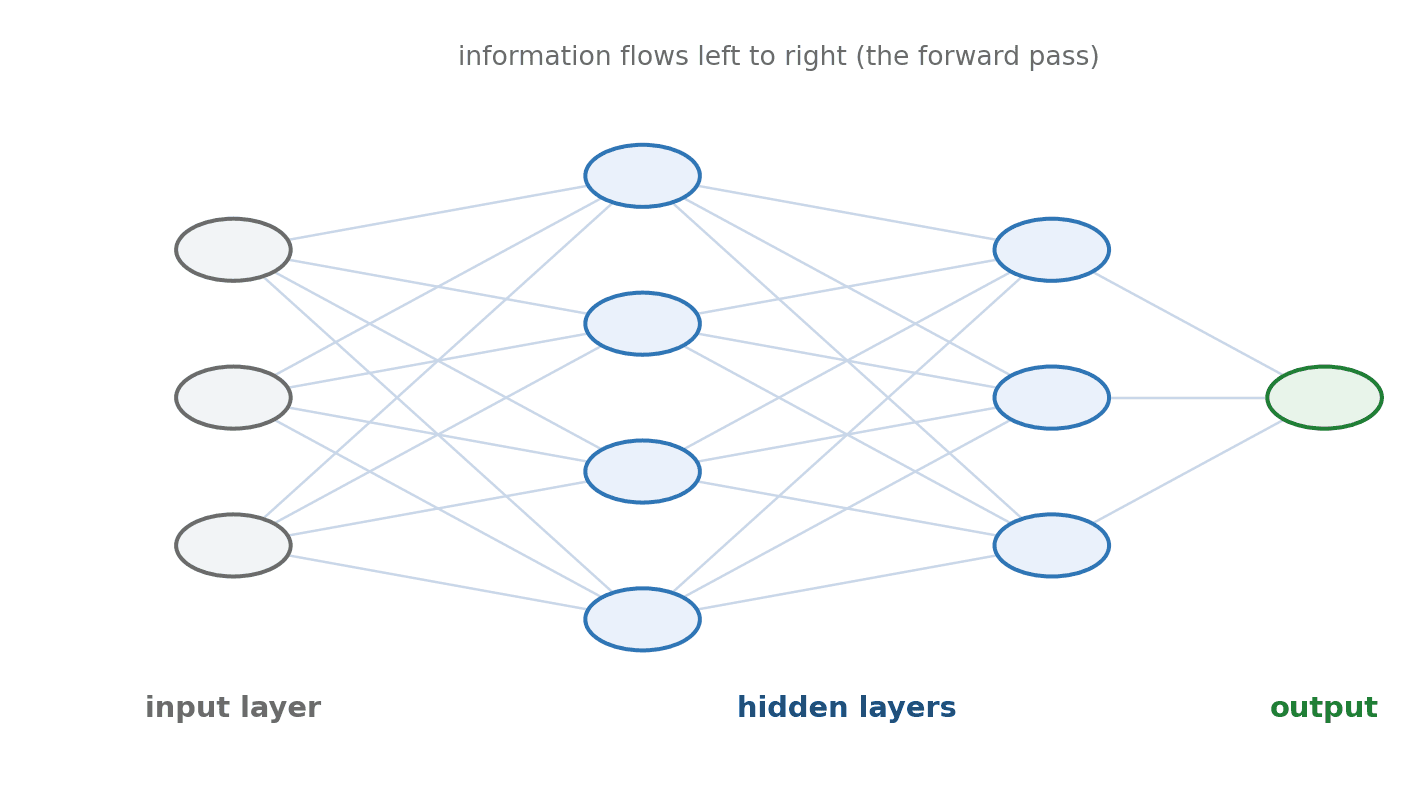
Now the final assembly. Stack layers so that the outputs of one layer become the inputs of the next, and you have a neural network. The first layer is the input layer, the last is the output layer, and any layers in between are called hidden layers. When there are many hidden layers, we call the network deep — and that is the entire origin of the term deep learning.
Information flows forward, layer by layer: raw inputs enter, each layer transforms them a little, and the final layer produces the answer. This forward flow is called a forward pass.
What Do the Weights Mean?
Here is the most important idea in the chapter. The weights are what the network has learned. A network's entire knowledge lives in its weights and biases — those numbers we have been passing in by hand. Change the weights and you change what the network computes.
When a network is first created, its weights are set to small random numbers, so it produces nonsense. Learning, which is the subject of the next chapter, is nothing more than the slow, careful process of adjusting those weights until the network's outputs become useful. We have built the machine; we have not yet taught it anything.
Summary
A neural network is built from neurons, and a neuron does four simple things: multiply each input by a weight, sum them with a bias, and apply an activation function that bends the result. The bend, or non-linearity, is what lets stacked layers learn complex, curved patterns instead of only straight lines. Neurons side by side form a layer; layers stacked together form a network, with input, hidden, and output layers — and many hidden layers is what makes a network "deep." All of the network's knowledge lives in its weights, which begin random and must be tuned.
That tuning is the missing piece. In Chapter 8 we discover how a network goes from random nonsense to genuine skill, by measuring its error and walking downhill — the gradient descent you first met in Chapter 5, now put fully to work.
Exercises
- 1Implement the `relu` and `neuron` functions from this chapter. Feed your neuron the inputs [2, 3] with weights [1, -1] and bias 0, and work out by hand what the output should be before running it to check.
- 2Change just the bias of your neuron from 0 to 5 and observe how the output changes. In one sentence, describe what the bias does.
- 3Build a layer of three neurons that all take the same two inputs but have different weights. Feed it an input and print the three outputs.
- 4Explain, in plain language, why a network without activation functions could only ever represent a straight-line relationship no matter how many layers it had.
- 5A network's weights start random. Explain what that means for its first outputs, and what 'learning' will therefore have to do to those weights. (Chapter 8 will confirm your intuition.)