
Chapter 22Parameter-Efficient Fine-Tuning: LoRA, QLoRA, and PEFT
The fine-tuning of the last chapter, taken literally, means adjusting *every* weight in a model. For a model with billions of weights, that demands enormous memory and computing power — far beyond a single ordinary machine. This chapter explains the clever family of techniques that changed everything by asking a liberating question: what if we only adjusted a tiny fraction of the model? The answer, **parameter-efficient fine-tuning**, is what put fine-tuning of large models within reach of individuals. We build the intuition from the ground up, no heavy mathematics required.
The Problem: Full Fine-Tuning Is Expensive
When you fine-tune a model the straightforward way, you update all of its weights — every one of the billions of numbers we met in Chapter 7. To do that, the training process must hold the entire model, plus extra bookkeeping for every weight, in memory at once. For a large model this can require many high-end GPUs costing a fortune, simply to make a modest behavioral change. For most people, full fine-tuning of a large model is flatly out of reach.
The Big Idea: Change Only a Little
Here is the insight that unlocked everything. To specialize an already-capable model, you do not need to rewrite all of it — you only need to make a small, targeted adjustment. So instead of updating every weight, parameter-efficient fine-tuning (PEFT) freezes the vast majority of the model and trains only a tiny number of parameters, often a fraction of a percent of the total. You get most of the benefit of full fine-tuning at a tiny fraction of the cost. PEFT is the umbrella term; LoRA is its most popular member.
LoRA: Low-Rank Adaptation
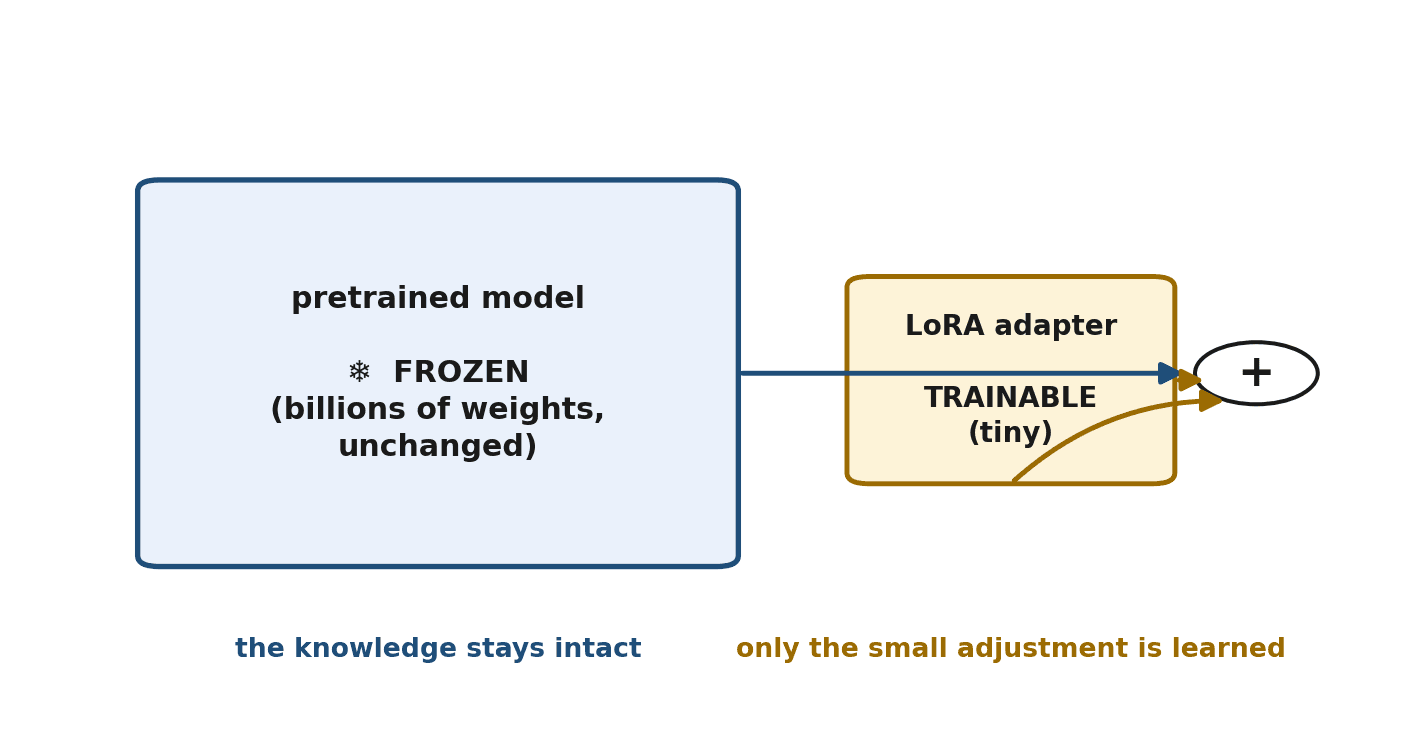
LoRA, which stands for Low-Rank Adaptation, is the technique that made PEFT mainstream. The idea is elegant. You freeze the original model completely — none of its billions of weights change. Alongside it, you add small extra components, called adapters, made of only a few new weights. During fine-tuning, only those tiny adapters are trained; the giant frozen model just provides its existing capability.
An analogy makes it concrete. Imagine you have a thick, authoritative textbook and you want to adapt it for a specialized course. You could rewrite the entire book — slow, expensive, and risky. Or you could leave the book untouched and add a thin booklet of margin notes and corrections that adjust how it is read. LoRA is the thin booklet. The original model stays exactly as it was; the small adapter captures the adjustment your task requires.
Why LoRA Works So Well
Why can such a small adapter do the job? Because the change needed to specialize a model turns out to be far simpler than the model itself. In the language of the technique's name, the adjustment is "low rank" — it can be captured by a small number of parameters even though the model has billions. You do not need billions of new numbers to express "answer in this style" or "focus on this domain"; a few will do.
The benefits cascade from this. The adapters are tiny to train, so fine-tuning fits in far less memory. They are tiny to store — megabytes, not gigabytes — instead of a whole new copy of the model. The original model is preserved, so you can always fall back to it. And, as we will see, adapters can be swapped in and out.
QLoRA: LoRA on a Diet
LoRA shrinks what you must train, but you still have to hold the big frozen model in memory while training. QLoRA shrinks that too, using a technique called quantization. Normally each of the model's numbers is stored with high precision, taking several bytes. Quantization stores them more coarsely — using far fewer bits per number — which dramatically reduces memory at the cost of a small, usually acceptable, loss of precision. Think of it as storing each number rounded to fewer decimal places: less exact, but far lighter.
QLoRA combines a quantized (compressed) frozen base model with trainable LoRA adapters. The result is striking: it becomes possible to fine-tune surprisingly large models on a single consumer-grade GPU — something that would otherwise require a cluster.
The Payoff: Fine-Tuning on Modest Hardware
Let us state the payoff plainly, because it is the whole point. Full fine-tuning of a large model might require multiple high-end GPUs and a serious budget. LoRA brings that down dramatically, and QLoRA can bring it down to a single affordable GPU — the kind a hobbyist or small team can actually access. These techniques are the reason fine-tuning large models is no longer the exclusive privilege of big labs. They democratized customization.
Swappable Adapters
A delightful bonus follows from adapters being small and separate from the frozen model. You can train many different adapters — one for a legal-writing style, one for a coding assistant, one for a customer-support tone — all sharing the same untouched base model. At use time, you load the base model once and snap in whichever adapter you need, swapping them like interchangeable lenses on a single camera body. This is far more efficient than keeping a separate full copy of the model for every task.
PEFT in Practice
In code, libraries make adding LoRA to a model remarkably simple: you wrap your base model with a LoRA configuration, and then train as usual — only now just the adapter learns. The illustrative shape below mirrors how the popular tools work.
# Illustrative: wrap a frozen base model with small LoRA adapters.
lora_config = LoraConfig(
r=8, # adapter size: small means few trainable parameters
target_modules=["attention"], # where to attach the adapters
)
model = add_lora(base_model, lora_config) # base stays frozen; adapters are trainable
print(model.trainable_parameter_count()) # often well under 1% of the total!
# From here, training is exactly the Chapter 21 workflow -- but far cheaper.
trainer = Trainer(model=model, train_data=train_data, epochs=3)
trainer.train()
model.save_adapter("my-style-adapter") # saves just the tiny adapterWhen to Use What
For nearly all fine-tuning you will ever do, LoRA or QLoRA is the right default. It is cheaper, faster, lighter to store, and gives results close to full fine-tuning for most tasks. Full fine-tuning is reserved for cases where you have ample resources and need the maximum possible change to the model — a rare situation for an individual builder. Start with LoRA; reach for more only if you hit a genuine wall.
Summary
Full fine-tuning updates every weight in a model and is far too memory-hungry for large models on modest hardware. Parameter-efficient fine-tuning solves this by freezing the model and training only a tiny number of parameters. LoRA, the most popular method, freezes the original model entirely and trains small adapters alongside it — the "thin booklet of margin notes" — which works because the adjustment a task requires is far simpler than the whole model. QLoRA adds quantization to compress the frozen model in memory, enabling fine-tuning of large models on a single consumer GPU. Adapters are tiny, preserve the original, and can be swapped per task. For almost all fine-tuning, LoRA or QLoRA is the right default.
We now know how to fine-tune efficiently. Chapter 23 zooms out from mechanics to purpose, examining the two-stage process — instruction tuning and alignment — that turns a raw base model into the helpful, well-behaved assistant you actually want.
Exercises
- 1Explain, in plain language and using your own analogy, what LoRA changes during fine-tuning and what it leaves frozen. Why does this save so much memory?
- 2Compare full fine-tuning and LoRA for a large model in terms of trainable parameters, memory needed, and storage size of the result. Why is LoRA's saved output so much smaller?
- 3Explain what quantization does and how QLoRA uses it to make fine-tuning possible on a single GPU. What is the trade-off?
- 4Describe the 'swappable adapters' benefit. Give a concrete example of three different adapters you might train on one shared base model, and why this is better than three full model copies.
- 5If you have a GPU or a suitable notebook environment, run a small LoRA fine-tune and report the number of trainable parameters versus the model's total. If not, describe the steps you would take and what you would expect to see.
- 6Explain when you would choose full fine-tuning over LoRA, and why that situation is rare for an individual builder.